Chapter 1
I didn’t expect the instructions to be so simple and linear. I figured it would ask me to do something instead of giving me step-by-step instructions down to the button to press.
My map after editing the public school symbology of the schools:
I funked around with the school walking areas and changed the color/added an outline. The outline helped me visualize where zones end but it does block up the map a bit with overlapping outlines. The color selection also feels inverted to human bias in color. The fact that the furthest walk is green is a bit confusing and should be considered if this map was ever used:
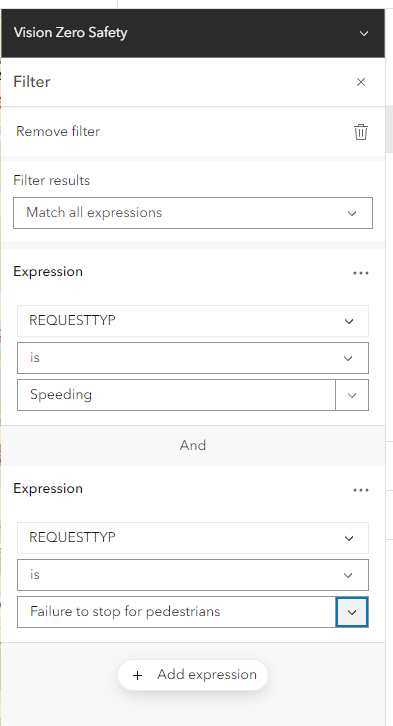
I added filters to the vision zero safety layer. These are going to minimize the amount of data points I see to only the selected expressions:
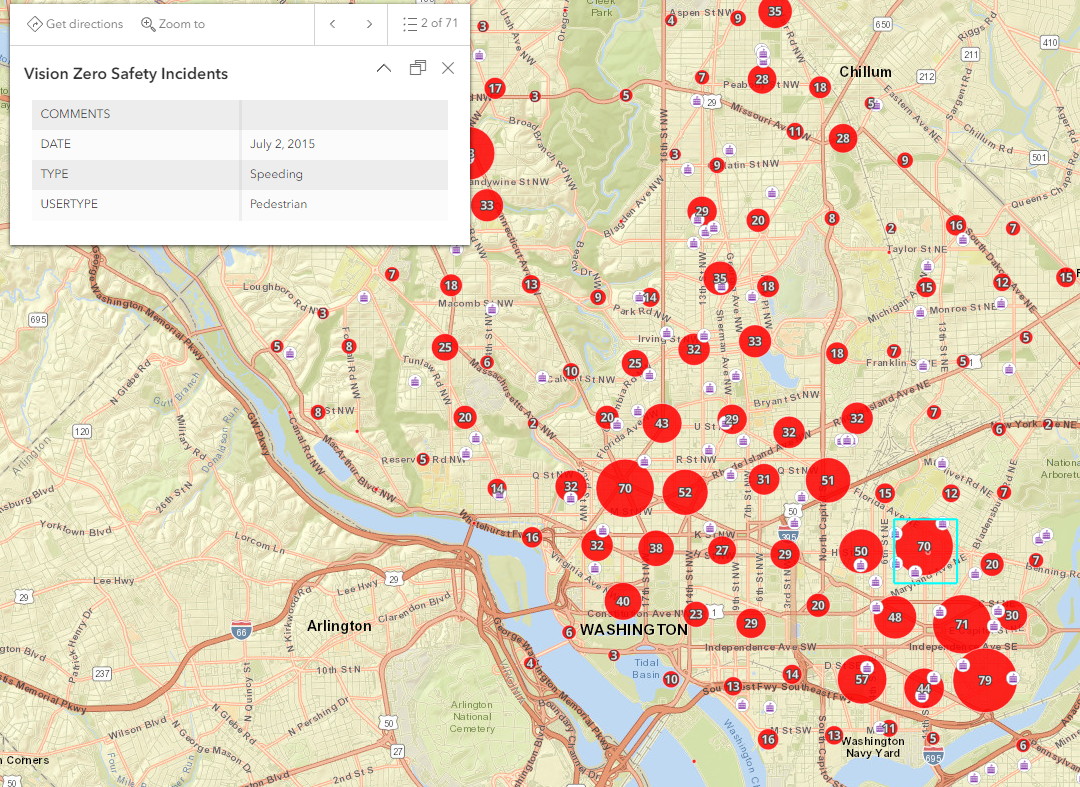
This next step required a little going astray from the book. It asked me to open the “clustering” tab but that doesn’t exist anymore, it has been renamed to “aggregation”. This is one of those reminders that things do update and change just a bit. But here’s my cute little clustered map of danger zones for pedestrians after it has been properly configured for fields:
Chapter 2
2.1
So far this work is super helpful for those who haven’t used ArcPRO before, but for those who have this feels like a drag. I understand starting from the bottom but some of this stuff is things I don’t even think about when I do them now.
I’m not sure if using the control key for selection is an Apple thing but I had to hold the shift button to select the 5 cities.
2.2
Opening the symbology tab was weird. I don’t often use the catalog tab as you have to manually open it to get to it. I can easily right-click the layer and select symbology. Just a reminder that there’s lots of ways to make something happen.
Here’s me messing around with distance measurements. The distance form Cape Town to Alexandria is 20,663.81 miles!
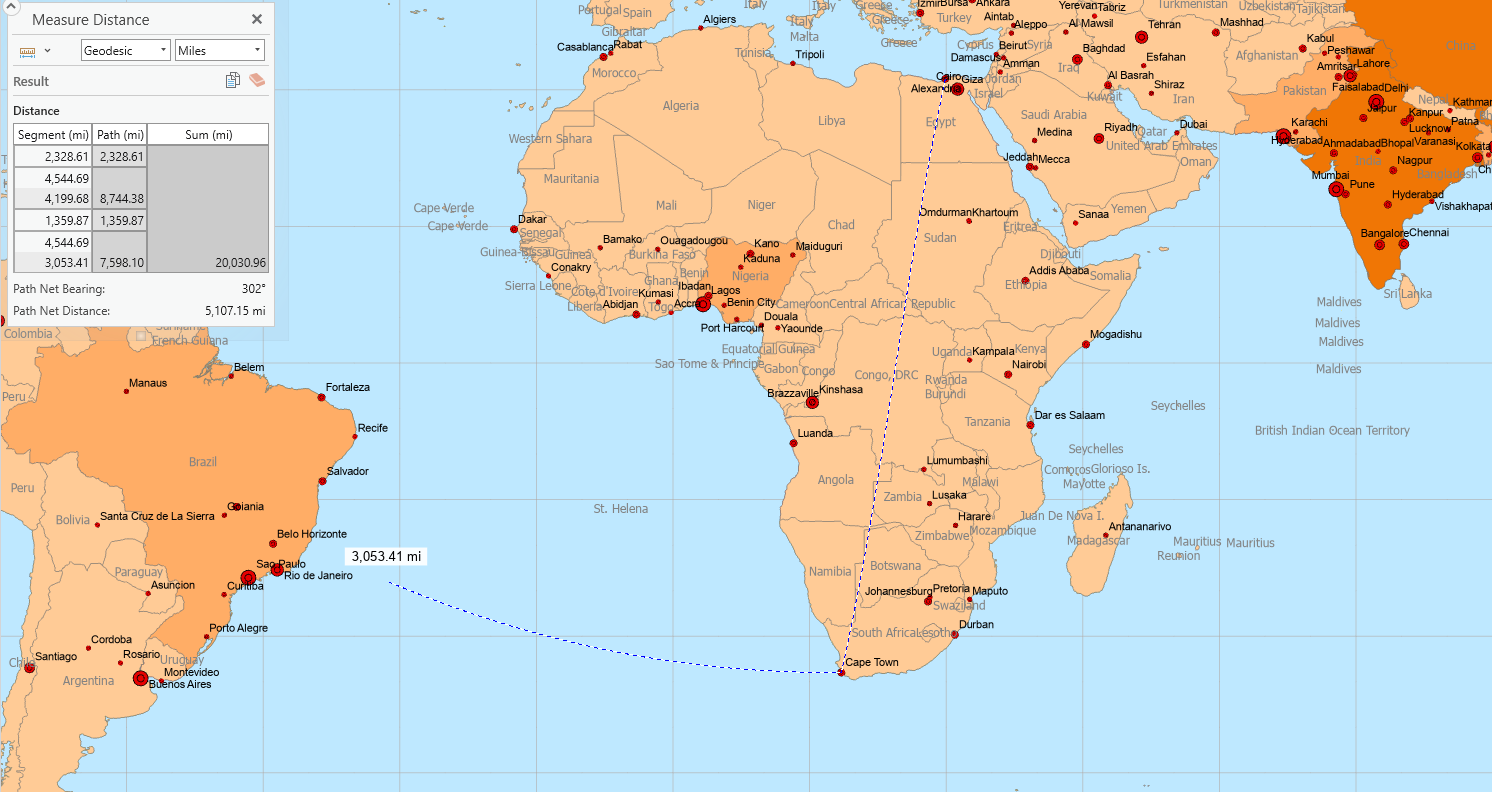
2.3
I’ve never made 3D images in Arc before, it looks so cool. Here’s my little linked map moment:
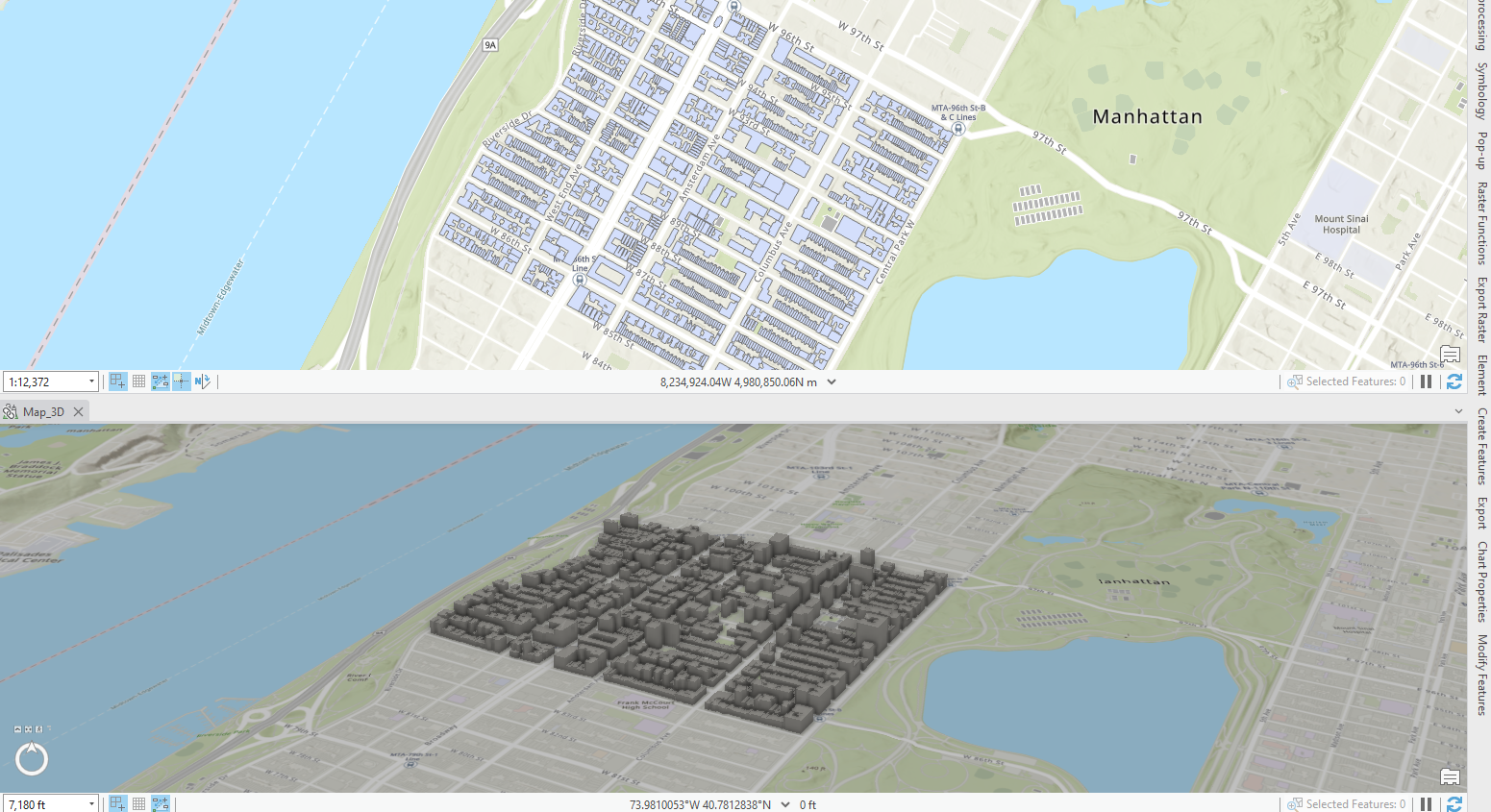
Chapter 3
I don’t like clicking the data tab to access the attribute table. I would rather right-click the layer to open it. The “new expression” button has also been changed to a “new clause” button instead. It’s weird though because it’s still labeled as expressions.
The export features have also changed. So I wasn’t allowed to save but not rename the output. So I just created it with the default name but renamed the layer. I’m not sure if it will show under this name in the file location but it worked.
I was really familiar with this exercise. I was reminded how finicky classes can be sometimes when you enter values. It makes me nervous.
Using the geoprocessing tools I found that the naming for double (double precision) didn’t exist anymore there was only double (64 bit). I had to do this step twice, because I wasn’t sure what went wrong but it came out right the second time. It was still a little wonky but it turned out with the same values.
Using the attribute table is a little extra mathy for me. I try to grasp what I’m doing but it’s difficult to understand sometimes.
Read the fine print, I couldn’t use the infographics tool until I was logged into ArcOnline. Weird but glad I caught it. Still couldn’t do the infographics. I used the correct login but it wouldn’t work and locked me out for 15 minutes… I got this far though! I had the map and percentage stats so this was the last step.
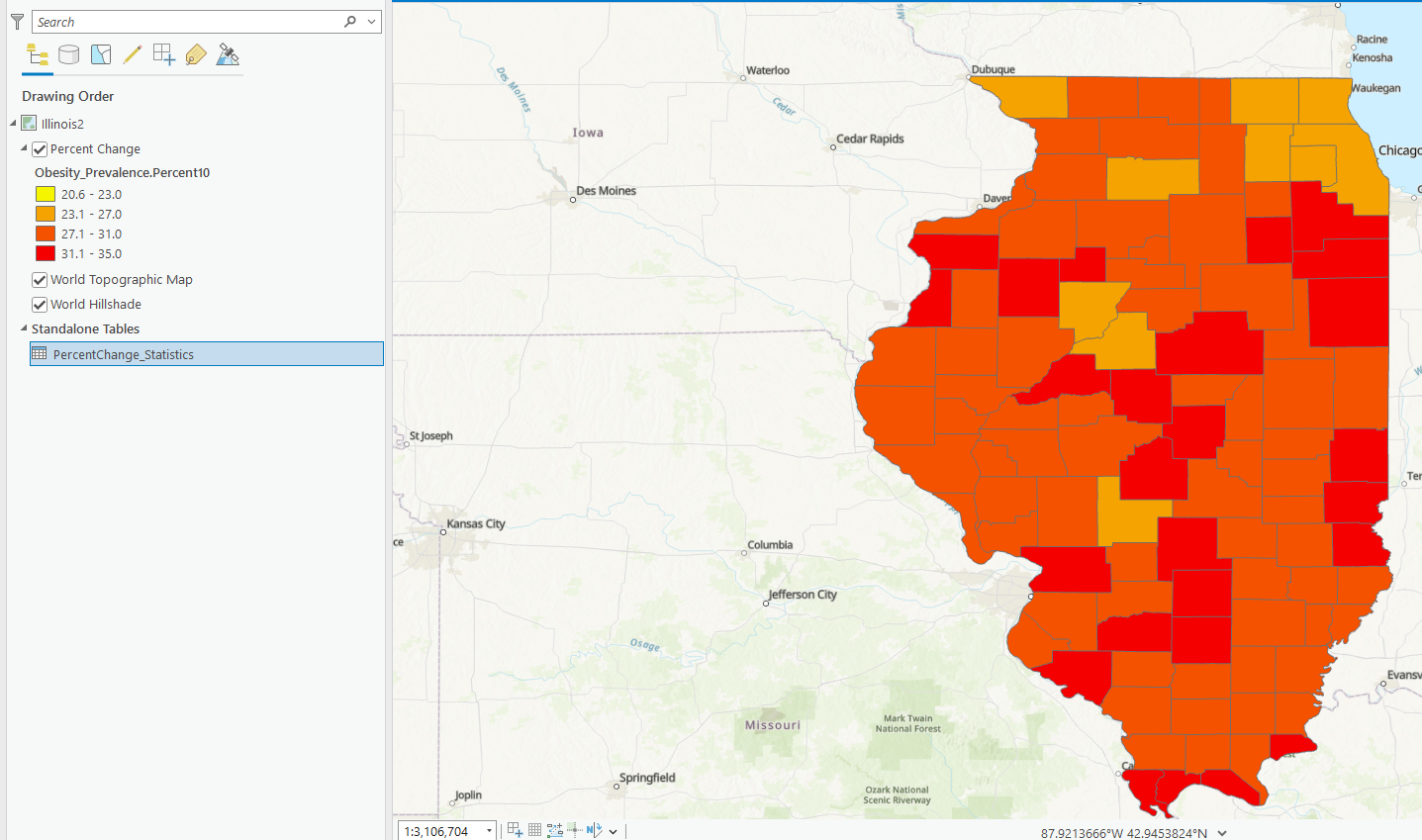
For the next exercise I was also having some troubles. When I imported the food deserts table layer, it was corrupted from the source. Google told me to repair the source but it said it was unavailable for the layer. After numerous location changes and removing and readding the file, it still didn’t work. Even opening it from the file to a new map it shows that it’s corrupted. So no stats here for me. I couldn’t do a spatial join either >:(
 weird text I’ve never gotten but got it saving the health data…I had to save it so I just updated it?
weird text I’ve never gotten but got it saving the health data…I had to save it so I just updated it?
Chapter 4
my beautiful city water things map:
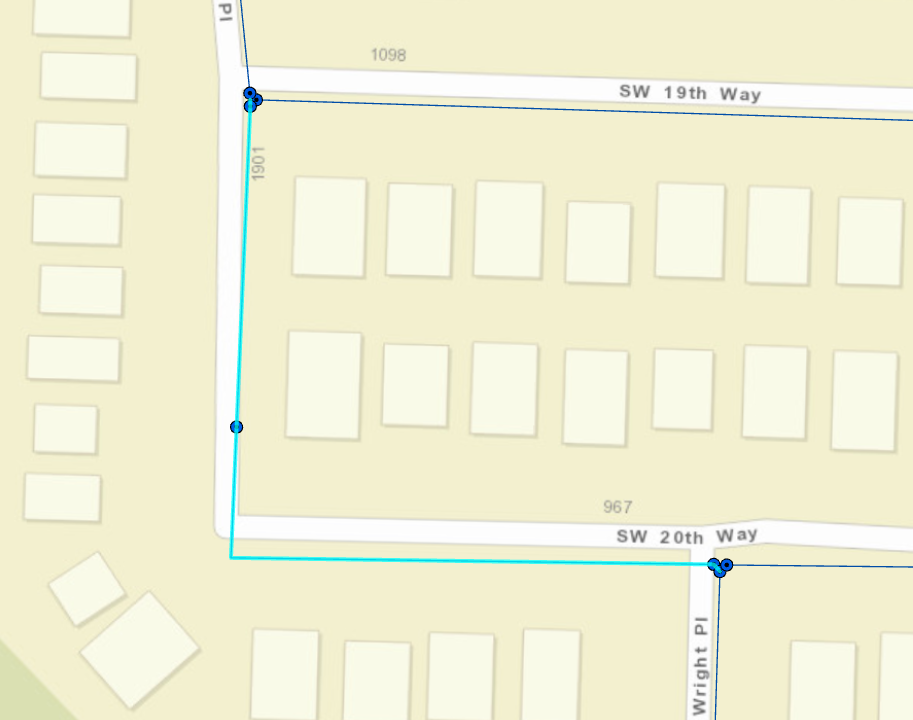
This city is safe, I repaired their waterlines:
My final map for chapter 4 after editing the water zones and highlighting it!:
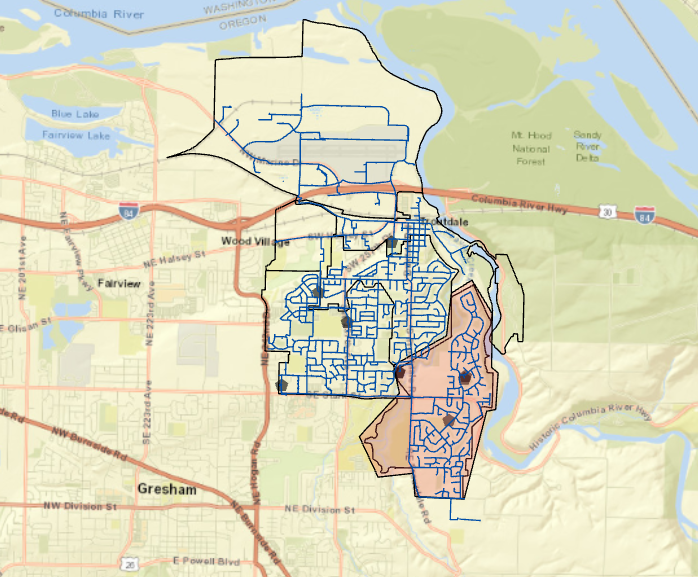
Overall theses exercises taught me new things and reminded me how to do some older things. I only missed two steps due to being stuck but I wasn’t ever overly frustrated. Hopefully, this continues with our projects but we’ll see!