Delaware County Data:
Zipcode: Contains all of the zip codes that are represeted in Delaware County. Data based on Census Bureau zip code files, and is updated on an as needed basis.
Recorded Document: Contains points for recorded documents. Documents include: vacations, subdivisions, centerline surverys, surveys, annexations, and miscellaneous documents within the county.
School District: Contains all of the boundaries for all of the school districts represented in Delware County. Updated as needed, and published on a monthly basis.
Map Sheet: Consists of all map sheets in Delaware County. All individual map sheets correlate to a numeric value to help distinguish between certain areas.
Farm Lot: Contains al of the farm lots in Delaware County. Data is based on US Military and Virginia Military surveys.
- Kind of confused on why the whole county is broken into farm lots, but i’m thinking it was how it was originally divied up during westward expansion. Not sure, though.
Township: Contains all 19 townships that make up Delaware County. Updated on an as-needed basis and published monthly.
Street Centerline: Represents the centerlines of all public and private roads within Delaware County. Updated on a daily basis as it is intended to support 911 emergency responses, accident reporting, disaster management, and more.
Annexation: Shows all of the annexations and conforming boundaries from 1853 to present day. Updated on an as-needed basis and published monthly.
Condo: Contains all condominium complexes in Delaware county. Based on data from the Delaware County Recorders Office.
Subdivision: Consists of all subdivisions and condominium complexes in Delaware County. Updated daily and published Monthly. A subdivision is a parcel of land that is divided into two or more pieces for sale.
Survey: Represents the many surveys of land within Delaware County. Updated daily and published monthly.
- Not sure what the surveys represent, but there is a lot of data in this shapefile.
Dedicated ROW: Represents all Right-of-Way lines within Delaware County. Updated daily and published Monthly.
- Not sure how this layer really works or what each section represents, but it looks interesting!
Tax district: Contains all tax districts within Delaware County. Data is based on the Auditor’s Real Estate Office for the county.
GPS: Identifies GPS monuments that were establushed in the 1990’s. Updated as-needed and published monthly.
- Again, not sure what these monuments are or what their GIS implications are, but looks interesting nonetheless.
Original Township: Consists of the original township boundaries in Delaware County. Unaffected boundaries before tax district changes.
Address Points-DXF: Contains points for all addresses in Delaware County. Maintined by the county Auditor’s GIS Office. Points represent the center of each building “as best as possible”.
Precinct: Represents all voting precints in Delaware County and is based on data from the County Board of Elections. Both updated and published as needed.
Hydrology: Consists of all major waterways in Delaware County. Data was enhanced in 2018 with the use of LIDAR data.
- LIDAR is light detection and ranging.
Building Outline 2021: Shows all building outlines in Delaware County. So much data in this layer that you need to zoom in to view the outlines.
Parcel: Represents all cadastral parcel lines within the county. Data maintained by the County Auditor’s Computer Aided Mass Appraisal system.
PLSS: Consists of all Public Land survey polygonsin the county. Data is also based on Military survey data from US and Virginia Militaries.
Street Centerlines- DXF: Another representation of street centerlines for the LBRS. The LBRS is The State of Ohio Location Based Response System.
Address Point: Spatially accurate depiction of certified addresses in the county. Used to determine the closest valid address from a set of coordinated for 911 responses.
2022 Leaf-On Imagery: Imagery from 2022 12in Resolution.
Delaware County Contours: 2018 Two Foot Contours for the county.
Building Outlines – DXF: Another representation of building outlines in the county.
- DXF stands for Drawing Exchange Format, which is a “legacy format originating in the CAD industry to exchange 2D vector data” as defined from the arcgis website.
Delaware County E911 Data: Another representation of accurate certified addresses in the county used for 911 responses.
ArcGIS:
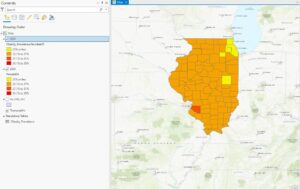
Here’s my final map with all three instructed layers along with a scale bar, legend, north arrow, and title. Unfortunately, my screenshot is horrible quality. Also, I had to unzip all of the files to be able to drag them into ArcGIS.
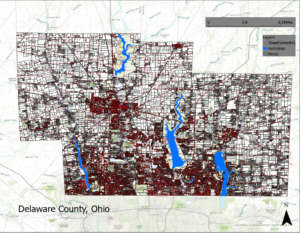
P.S. Thanks, other logan for the idea of creating a whole layout rather than just a screenshot with the visible layers.
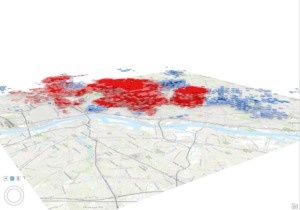
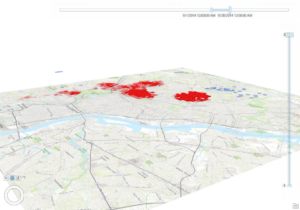
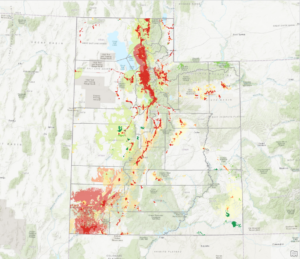
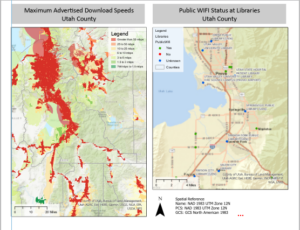


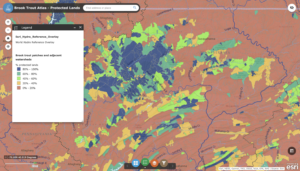
 Will Patterson, Ken DeVore. “Restoring Rare Trout to Its Native Range.” Esri, 6 Feb. 2019, www.esri.com/about/newsroom/arcuser/restoring-rare-trout-to-its-native-range/.
Will Patterson, Ken DeVore. “Restoring Rare Trout to Its Native Range.” Esri, 6 Feb. 2019, www.esri.com/about/newsroom/arcuser/restoring-rare-trout-to-its-native-range/.