1)
Common uses for geographic analysis: Mapping where things are, Mapping the most and least, Mapping density, Finding what’ s inside, Finding what’s nearby, Mapping change
GIS analysis is a process for looking at geographic patterns in your data and at relationships between features.
Process: Frame the question, Understand your data, Choose a method, process the data, Look at the results.
Geographic features are discrete (the actual location can be pinpointed; at any given spot, the feature is either present or not) , continuous phenomena(blanket the entire area being mapped, but a value can be determined at any given location), or summarized by area (density of a variable within area boundaries,.Data applies to entire area, but not any specific location within it).
Vector Model: Each feature is a row in a table, and feature shapes are defined by x,y locations in space. Analysis involves working with (summarizing) the attributes in the layer’s data table. Better for discrete features and data summarized by area.
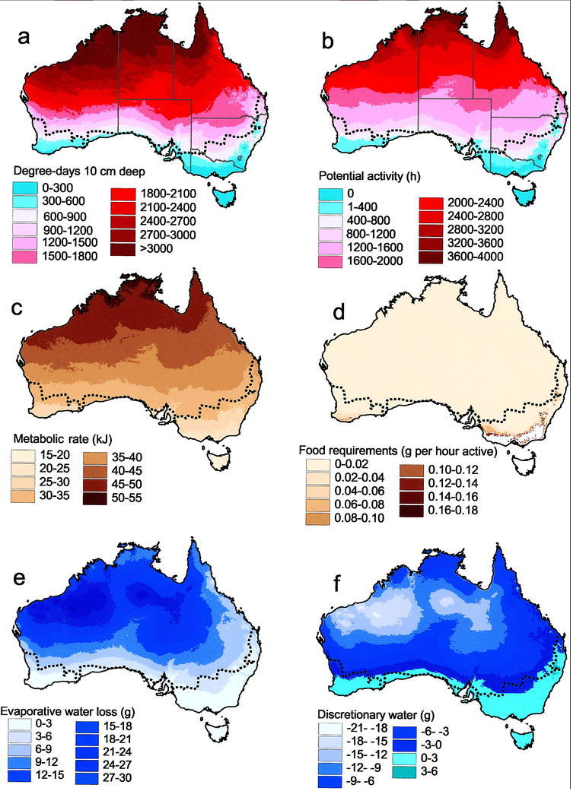
Raster Model: Features are represented as a matrix of cells in a continuous space. Analysis occurs by combining the layers to create new layers with new cell values. (must use perfect cell size: too small requires too much storage and takes longer to process, too large will cause detail and information to be lost). Better for continuous numeric values.
Although vector discrete features are usually best represented in vector models they are often better represented in raster models when multiple layers are being analyzed.
Types of attribute values:
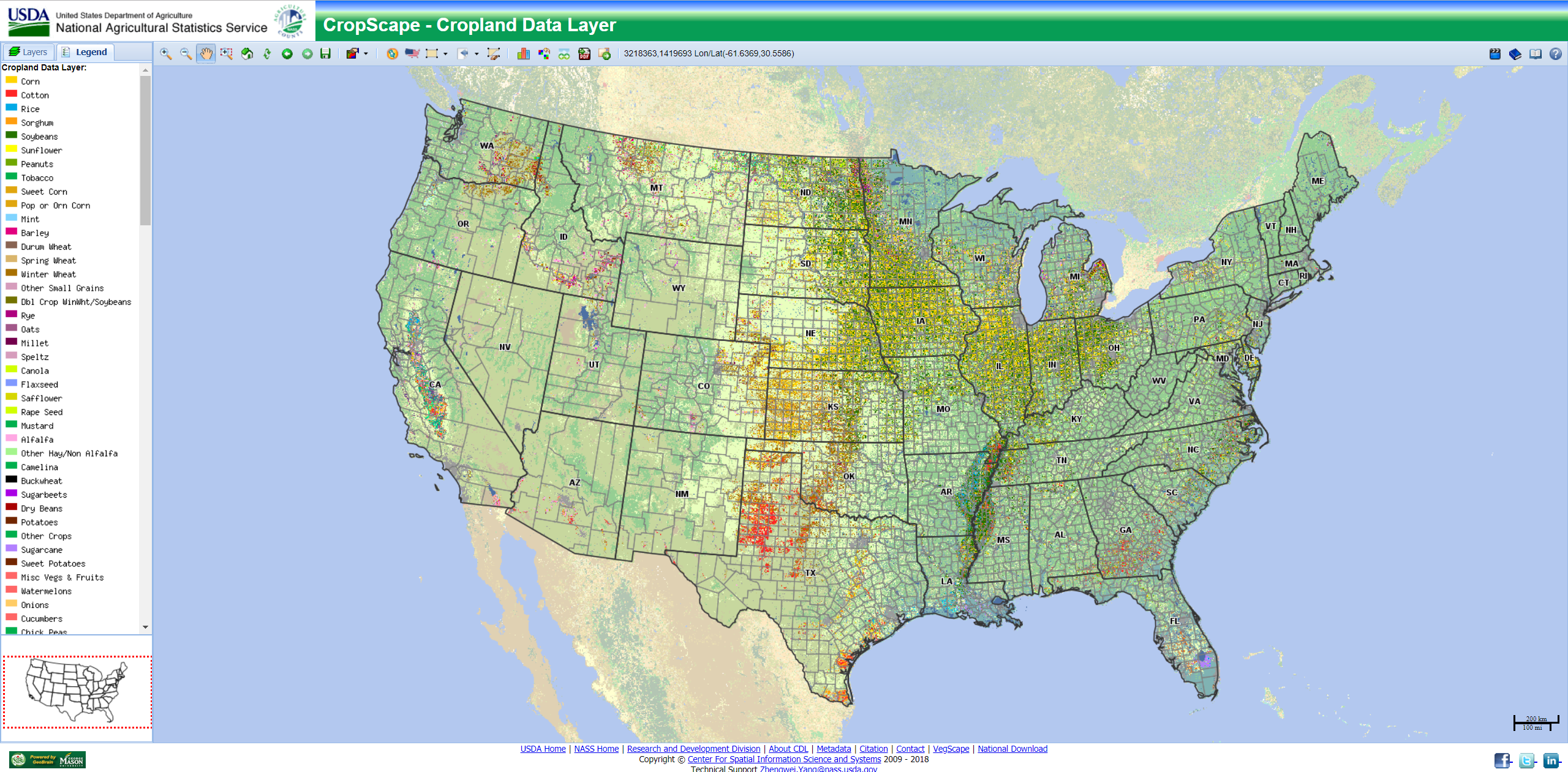
Categories: Groups of similar things for example the crime category could include theft, burglaries, assaults, etc.
Ranks: Ranks put features in order, from high to low. Used when measurements are difficult to quantify. Ranks are relative, so they are compared to each other.
Counts and Amounts: Hard data, actual numbers. Can be a measurable quantity associated with a feature.
Ratios: Show you the relationship between two quantities and are created by dividing one quantity by another for proportions or densities.
categories+ranks=noncontinuous / counts, amounts, and ratios= continuous
2)
Pay attention to distribution of features rather than the features themselves.
Should I have a question in mind, or even my hypothesis, before beginning the process of geographic analysis?
GIS stores information such as either a coordinate pair or a set of coordinate pairs to define shapes.
Subsets can be separate layers that convey information with more specificity to reveal patterns that possibly weren’t previously apparent when mapping all features.
Showing a subset of continuous data leaves the features without a context. 🙁
Using different colors or symbols for each type of feature in a category can show a more complex understanding of a specific area and how it functions. If the types within a category are very similar or overlaid it could be beneficial to use separate maps and compare rather than setting all of the data on a single map.
When mapping large areas the use of too many categories can make patterns difficult to see, but fewer categories can be beneficial at conveying patterns. Grouping categories can also be beneficial, for example rather than showing four types of industrial zoning on a large map; the use of one general industrial feature and a possible separate map of subsets could work better.
Use symbols that are easily discernible from each other!
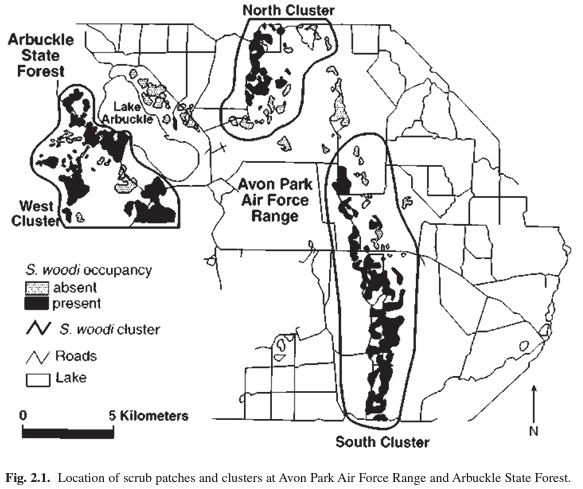
clustered: features likely to be near other features
uniform: features less likely to be found near other features
random: features equally likely to be found anywhere
To determine whether patterns are meaningful the analyst must use statistics to measure and quantify the relationships between features.
How does an analyst determine whether a pattern is meaningful or simply caused by chance?
3)
Mapping using quantity rather than just features gives a more in-depth map that could be more helpful to find places that meet criteria, need action, or to see relationships.
Mapping most and least can be used in many different ways that I had never considered previous to reading this chapter.
Just like in writing you must keep your purpose and intended audience in mind. Are you exploring the data yourself or creating a map to convey information to someone else? “In many cases, you’ll start by exploring the data to see what patterns emerge and what questions arise, and later create a generalized map to reveal specific patterns” (56).
Mapping counts and amounts:
discrete features (ex; number of employees at each business)
continuous phenomena (ex; annual precipitation at any location)
summarizing by area (ex; mapping number of employees per square mile)
Mapping ratios:
Proportions show you what part of a whole act quantity represents
Densities show you where features are concentrated
Ranks can be indicated using varying words- like high, medium, low- or using numerical values- ie 1-10-.
Classes group features with similar values by a signing them the same symbol.
Standard classification schemes:
Natural breaks (Jenks): Classes are based on natural groupings of data values.
- good for mapping data values that are not evenly distributed, places clustered values in same set.
- difficult to compare with other maps, difficult to choose right number of classes
quantile: Classes contain an equal number of features
- good for comparing areas that are roughly the same size
- good for evenly distributed data
- if areas vary greatly, a quantile classification can skew the patterns on the map
equal interval: The difference between the high and low values is the same for each class
- presenting information to a nontechnical audience
- mapping continuous data
- difficult to class clustered data
standard deviation: Features are placed in classes based how much their values vary from the mean
- good for displaying data around the mean
- very susceptible to being skewed from outliers

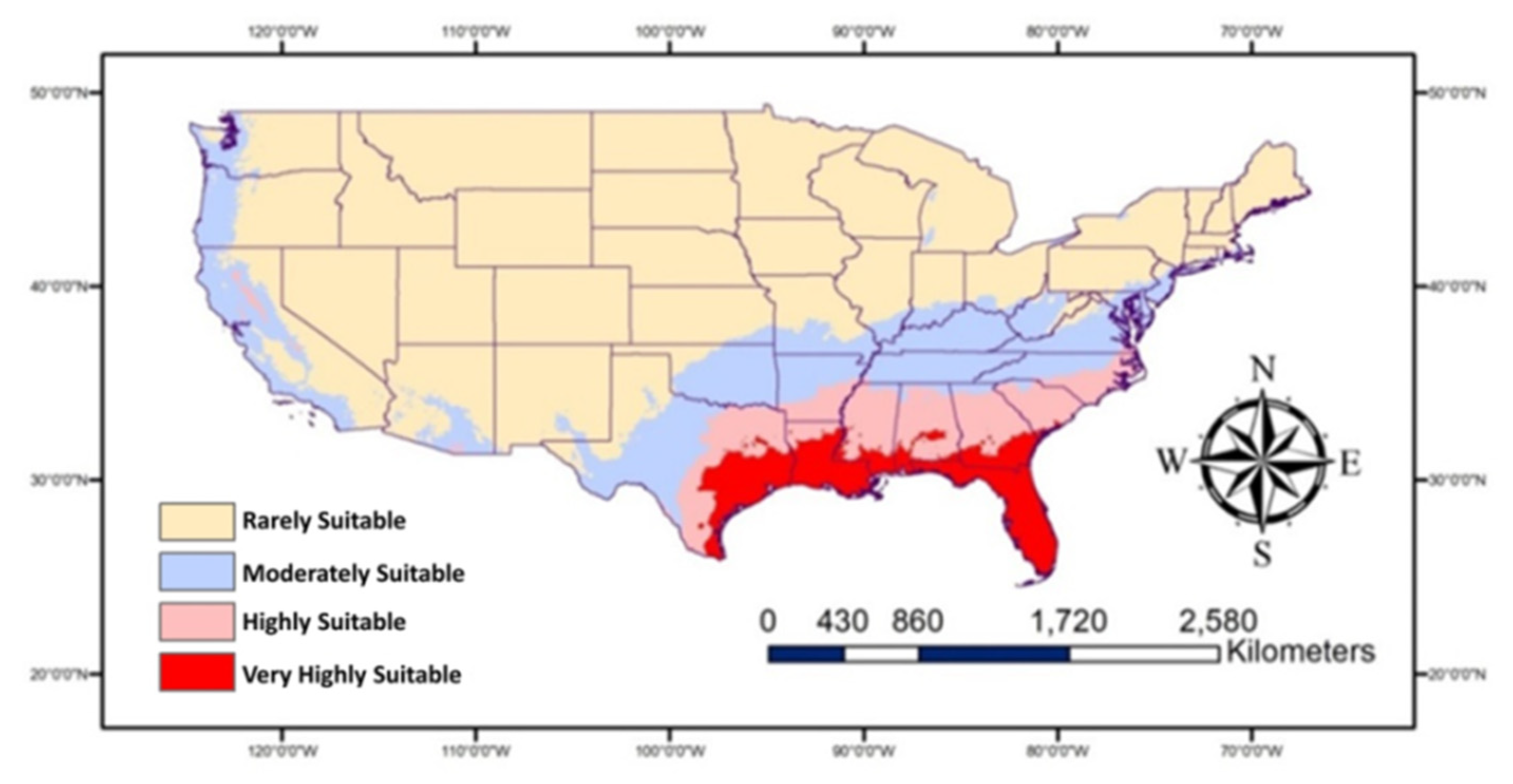
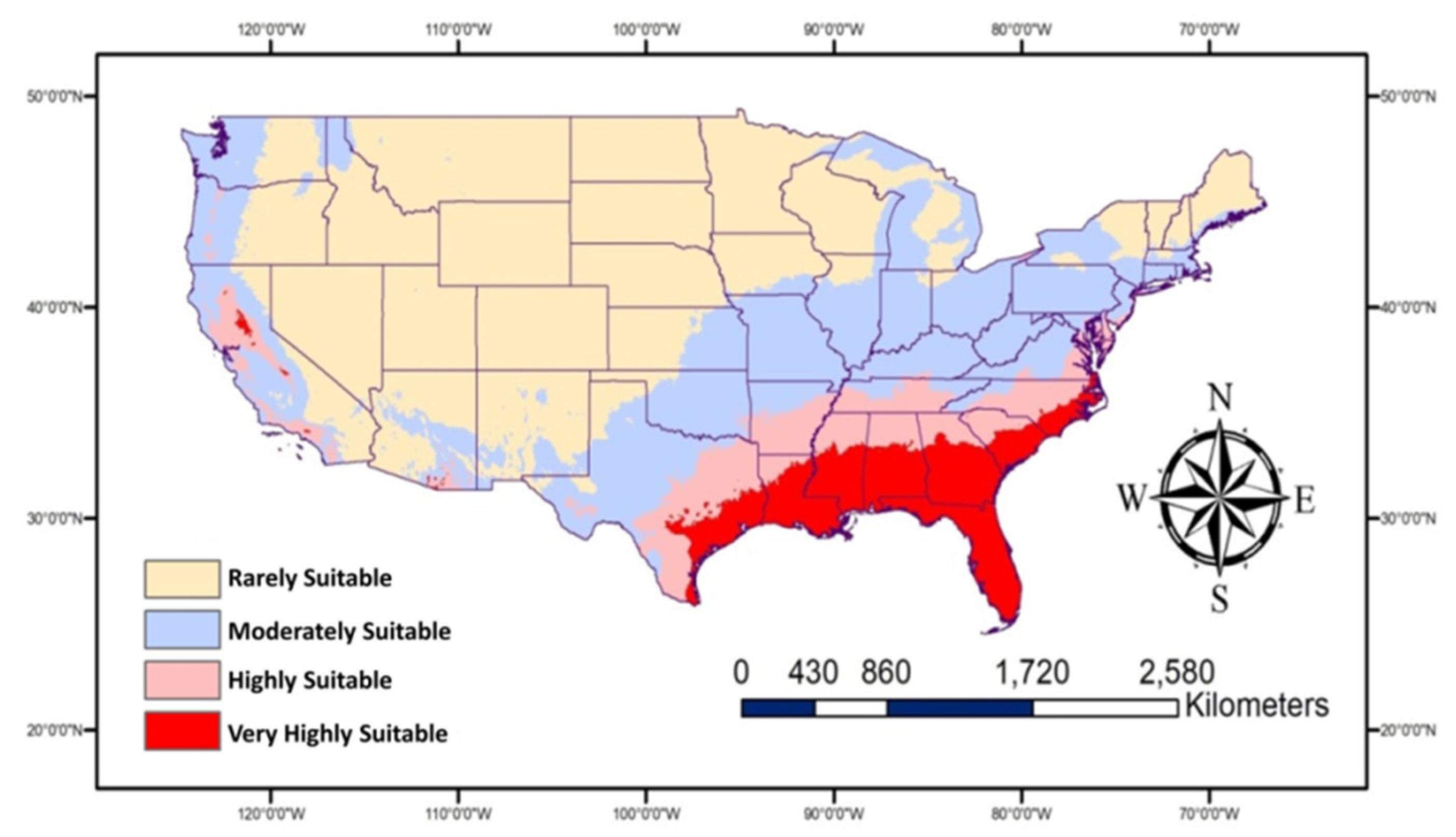









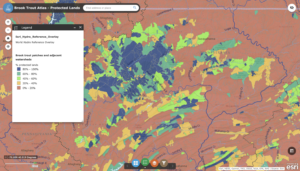
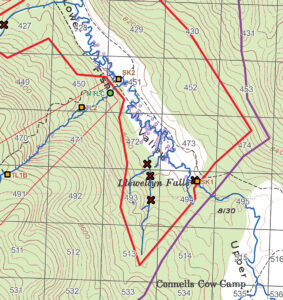 Will Patterson, Ken DeVore. “Restoring Rare Trout to Its Native Range.” Esri, 6 Feb. 2019, www.esri.com/about/newsroom/arcuser/restoring-rare-trout-to-its-native-range/.
Will Patterson, Ken DeVore. “Restoring Rare Trout to Its Native Range.” Esri, 6 Feb. 2019, www.esri.com/about/newsroom/arcuser/restoring-rare-trout-to-its-native-range/.


{kind=link}