Mitchell Chapter 1-3 Summaries
Chapter 1
The book starts off with a question how important GIS is and what it’s used for/applications. The book additionally tells you what tasks in GIS are common such as mapping where things are, mapping the most and least, mapping density, finding what’s inside, finding what’s nearby, and mapping change. The most important things to consider when performing a GIS task are how it will be used and who will use it according to the book and personally I agree. Essentially when you conduct a GIS survey you should choose how much effort would be appropriate for the task. If its for a court case on ENVS policy on deer hunting you should find all the data to who and in what county someone killed more deer than is allowed but if it’s a survey then maybe you list the total for the state in general. Additionally for GIS there is a 5 step method to analysis processing framing the question, understanding the data, choosing the method, processing the data, and evaluating the results.These steps ensure that analysis is systematic and produces reliable outcomes. Another key point in the chapter is the distinction between different types of geographic features: discrete features such as businesses, parcels, or rivers; continuous phenomena such as temperature or rainfall; and data summarized by area like population totals within a county. Each of these can be represented using either a vector model, which stores features as coordinate-based points, lines, or polygons, or a raster model, which represents space as a grid of cells, each with its own value. Attributes linked to features are also critical in analysis, and they can be categorized as nominal (categories), ordinal (ranks), interval/ratio (counts or amounts), or ratios that standardize values like population density. Finally, the chapter emphasizes basic operations like selecting, calculating, and summarizing attributes in tables, which allow analysts to extract new information from raw data.”
Chapter 2
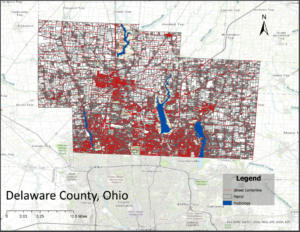
The chapter talks about deciding what to map and what to include in a GIS map. According to the book when mapping a layer you designate a symbol to each type of data. A layer is a collection of geographic data pertaining to one type of information about the place you are mapping. For example one layer could be a street, another could be houses, and finally one can be the cars if you’re mapping traffic data for neighborhoods. The book emphasizes that the map should be tailored to the audience you’re presenting it to. Additionally for every point you plot you should have the cords and optionally the data corresponding to it if necessary. When you map features by types you should include a code that identifies its type of info. Additionally when creating a category you need to specify the layer’s data on the data table and assign the appropriate value to the feature. When mapping a layer you can include multiple different types of info into one layer with a symbol for each or one type per layer. You can additionally categorize information if you choose or hierarchically rank each data under a symbol/shade. Sometimes if a category is complex you can create different maps per category. The book says displaying types of categories may make it easier to see how different categories are related. The book sets a limit to categories as well and emphasizes that if you’re writing multiple categories onto one map then 7 is enough. Additionally the distribution of features affects the data. “When a map shows many small, scattered features instead of large continuous areas, it becomes harder for readers to distinguish between categories. In cases where features are spread out, it is possible to display more categories, but if the features are densely packed, fewer categories should be used for clarity.
Chapter 3
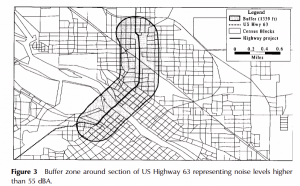
Chapter 3 of the book focuses on how to interpret data after it has been gathered. It offers practical guidance on what the data can reveal and how to present it effectively. For example, mapping patterns with similar features and categorizing them can help in selecting the most appropriate data for an assignment. The chapter also introduces the concept of continuous phenomena and area. In GIS, an area is defined as the amount of space inside a boundary on a map, typically measured in square units. The book explains how areas can be displayed using graduated colors, contours, or 3D perspective views. Interpreting data in terms of area can involve shading each region based on its value or using charts to show the amount of each category within that area. GIS professionals often summarize individual locations and linear features within areas to help communicate patterns more clearly. A key part of data interpretation involves understanding quantities, where features are symbolized based on their attributes. Chapter 3 discusses the use of counts and amounts, which show the value of each feature and allow for comparison across features. These can apply to both discrete features and continuous phenomena. However, the book notes that using counts alone can skew results if the areas differ in size. To address this, it recommends using ratios-created by dividing one quantity by another-to reveal relationships between values more accurately. The chapter also introduces ranks, which help by assigning a hierarchy to combinations of attributes. Finally, it explains how to set up classes to group counts, amounts, or ratios. Classifying data helps determine the types of quantities being dealt with and allows for clearer, more consistent analysis and presentation.