Chapter one:
Chapter one of Getting To Know ArcGIS to me is divided into two parts. The first part is an introduction to GIS and all the basic concepts. This part was very similar to Mitchell’s book. Terms like raster, vector, attributes, layers, and base maps were also referred to again in this book. The first page also mentions hardware as an essential part of GIS, which was interesting to me because I’ve never considered it one. Examples of solving global problems with GIS were brought up. Hardware was also mentioned as an essential part of GIS which seemed interesting to me since I didn’t consider it as one.
The second part is more about ArcGIS and ArcGISPro. ArcGISPro is a part of the ArcGIS Desktop suite and is designed for GIS professionals to use. ArcGIS provides ready-to-use spatial data and related GIS services, such as global base maps, geocoding, and much more. ArcGIS Pro is organized into projects which contain maps, layouts, layers, tables, etc. It makes use of ArcGIS Online, which provides a backdrop as you add on your layers. It also contains geoprocessing tools that involve an operation that manipulates spatial data, such as creating a new dataset or adding a field to a table. The chapter then instructed on using the ArcGIS software.
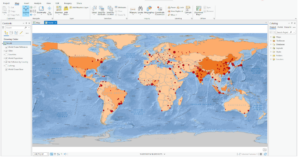
The first step was to log in to ArcGIS Online, which was nice since I got to play around with the software without having to download it. There were a lot of public maps and features available, which could help beginners like me to get used to the software. There was a variety of base maps provided. Turning on all the layers on the map suddenly made it crowded, however, there were advanced features available that helped make it more readable. The layer modifications feature seemed cool and practical, which could also help us analyze.
Chapter Two:
The second chapter acts as an introduction to ArcGIS Pro. I struggled through it a bit. I had a hard time importing the data because I didn’t know where to download it from. However, since all the students were in the lab, we figured it out together(Turns out the data was in the preface!). I also struggled with opening the catalog pane, but I was able to navigate the software once I imported the data.
In exercise 2A, different layers could be turned on and off based on what the user is trying to analyze. There were a couple of questions that could help provoke analytical thinking in the reader, which was interesting. There were also filtering features that would help explore quantifiable values effortlessly.
In exercise 2B, I closely looked at symbols and the configuration of features. Symbology refers to the way GIS features are displayed on a map. They are useful for making the map look more presentable and conveying meaning to the readers. Here, “Cities” is a graduated symbol because the larger the population, the larger the symbol. For symbology, I chose small pink circles because I thought they looked cute. I also like how multiple base maps with dynamic graphics were provided to add to the existing map.
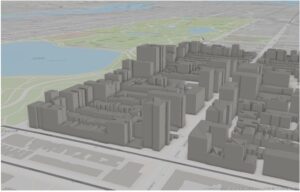
In exercise 2C, I worked on 3D maps, which are more engaging when compared to 2D ones. I struggled with importing the database, but with a few clicks here and there, I figured it out. The chapter mentioned Extrusion — the stretching of flat 2D features vertically so that they appear three-dimensional. The maps can also be easily converted from 2D to 3D. Exploring the 3D maps is one of the coolest things I’ve ever done so far this semester.
Chapter three:
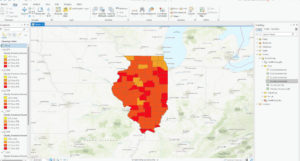
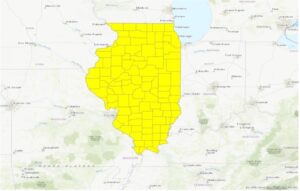
The third chapter closely focuses on geospatial relationships. The chapter referred to combining datasets and deriving statistics, and it reminds me of a project I did recently where I used Xarray and Python to perform Climate Geospatial Analysis. In exercise 3A, I struggled A LOT with opening the database. One would think the third time’s the charm but clearly not. As I went ahead, I found a couple of confusing things: Selecting a particular portion on the map(Illinois Boundary) and the mentions of future chapters. Some terms were briefly explained, and then had a ‘TIP’ section that said we’ll study them in the next few chapters. I’m sure the author had a good reason for doing so, but this kind of+ sidetracked me from my path. I was able to add Illinois later using the Select By Attribute Feature. I was also stuck on exporting the selection to a new dataset for hours and hours. I also found some differences in the software and the text(slight ones), which took me a while to figure out.
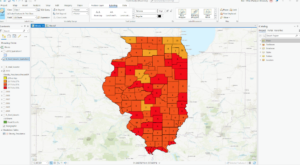
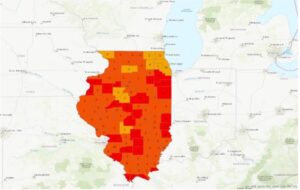
In exercise 3B, we incorporated tabular data into our existing attribute table. Columns in this exercise were called fields. I found appending the tables and data very easy. Next, we worked on adding graduated symbols, which is the process of using the same symbol with different colors for features. It was easy for me to figure out how to add those to the map, and the software was also very accessible. Different classification methods mentioned in the previous textbook(Mitchell) were also referred to here. Adding maps from different layers for all the years from 2004-2010 and comparing them was fascinating.
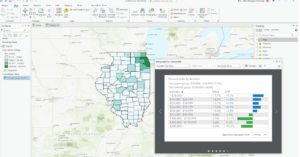
In exercises 3C and 3D, we calculated data statistics and connected datasets. I struggled with creating a null field in this one. However, I was slowly able to figure it out. I found it easy to calculate summary statistics and examine infographics. Connecting the spatial datasets in exercise 3D helped in the analysis and was also deemed insightful.
Chapter four:
In chapter four, we focused on creating and editing datasets. Accessing the database and getting started with the project was much easier this time. In exercise 4A, I got comfortable with using the geoprocessing pane. I ran into some errors while incorporating ‘Valves.csv’ into the map but figured it out with some time. I also learned how to set an attribute domain. I found some differences between the data shown in the software and the one in the textbook. However, I was able to add it to the map properly.
In Exercise 4B, I learned snapping and got comfortable with terms like vertex, endpoints, edge, or intersection. I struggled a lot here with the editing features and spent hours on getting my map with the one on the software. I found this exercise to be the hardest of the three exercises in this chapter. In exercise 4C, I split the water pressure zones into two parts and explored their differences. I found it easy to snap, split the sections, and understand the instructions given in the textbook. I also found it easy to merge the polygons and modify lines and points.
Chapter five:
Chapter five focused on facilitating workflows, creating a geoprocessing model, and using Python in GIS. Opening the database was easy, and I was glad I was making progress. In exercises 5A and 5B, we worked on performing repeatable workflow tasks and geoprocessing models. It was easy to get through and did not stress me out as much as the first three chapters. I found the ‘Tasks’ feature in the View tab very helpful as they had clear-cut instructions and made selecting specific places easy.
In exercise 5C, we incorporated Python into the software, which I found exciting. I want to keep finding ways where GIS can be integrated with technology more. I got through the entire exercise quite comfortably. I found that a lot of the things in this exercise I have done before for other projects in a similar manner. I enjoyed this exercise a lot.
Overall:
I struggled quite a lot while going through these chapters. However, by the end, I was able to pick up the pace and apply some sort of knowledge. I think with enough practice, I can get somewhere with ArcGIS Pro. I also want to take this time to thank all the people who show up to the lab at 9 am every day because I’ve been stuck a few times and we’ve all helped each other out.
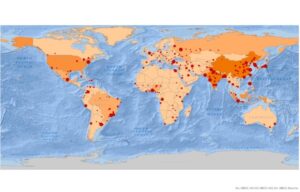
Here are some of the screenshots of my maps while I was working on them: