Chapter 1:
The most common GIS analysis tasks are mapping where things are, mapping the most and the least, mapping density, finding what’s inside, finding what’s nearby, and mapping change. These are all analysis tasks that we can do in GIS, with a plethora of different datasets. GIS analysis is the process for looking at geographic patterns in your data and at relationships between features. There are four types of geographic features, discrete features, continuous phenomena, features summarized by area, features summarized by area. The two distinct methods or models used to represent geographic features in GIS are vector and raster. A vector model involves each feature as a row in a table, and each feature represents either discrete locations, events, lines, or areas. Differently, the raster model represents features as a matrix of cells in continuous space. I have some experience working with both vector and raster, and have never fully understood what the difference is and what is actually going on within the computer. Even after reading this section of the chapter I still feel somewhat confused about what is really going on. Each individual layer represents one attribute and almost all analysis happens by combining layers to create new layers with new cell values. Attribute values are important for understanding geographic attributes. Attribute values are categories, ranks, counts, amounts, and ratios. Very simply, categories are groups of similar things which allow you as the researcher to organize data. Any feature with the same value in a category is alike in some way, and different from a plethora of other features with other values. It is a sorting tool. Ranks are just what they sound like, they rank features in order from high to low and are often used when direct data isn’t available. Counts and amounts show total numbers. Count being the actual number of features on a map, and an amount being any measurable quantity associated with a feature. Ratios show relationships between quantities and are made by dividing one quantity from another. Ratios are important when disparities exist between features or areas, such as large and small geographic areas.
Chapter 2:
I think the idea of altering or catering a map to specific stakeholders is very interesting and plays into the discussion on making a map. I’m excited to see what the chapter has to say about this section. When thinking about deciding what to map, it is important to recognize what information you are ultimately wanting to display or understand through your analysis of the map and to think about how you will use your map. These questions guide what features are displayed or contrasted and ultimately the answers to these questions shape the choices of the mapmaker and ultimately the impact of the map. I’m confused about the section titled “making your map”, it uses the phrase “you tell GIS which features you want to display and what symbols to use to draw them”. I don’t understand how the symbols and drawing function and what this does or does not do to a map. Using a single layer (mapping a single type) draws all feature types with one single symbol, which can still reveal patterns, even though they solely show where features are. Conversely, using a subset of features allows you to map all features in a data layer based on a category value. This allows you to map all crimes, select burglaries and map only those, even selected commercial burglaries from there. This layering allows the discovery and illustration of more and more patterns. I’m starting to have some more clarity about symbols and drawing, I think reading about different ways to map is helping me better understand the role of layers. You can also map using categories. You would therefore be drawing features using different symbols for each category value. This can potentially provide insights about how places work at a deeper level than simply single groupings, like crop type (simple) and species (complex). It is important to choose the symbols you use to display your map categories because they help to reveal patterns within the data. This is a section I will definitely dog-ear and come back to when it is time to pick symbols. Ultimately, if you do all the stuff listed above, you should be able to potentially recognize some geographic patterns within the maps you create. This will come to fruition if the map presents information clearly. Things to look out for are features that appear to be clustered, uniformly spaced, or randomly distributed.
Chapter 3:
This chapter begins by discussing the ability map makers have to add more meaning and value to their maps by mapping “most and least”. This involves mapping features based on quantities which can add another level of information (more than just the locations of features as discussed in the previous two chapters). In order to achieve this, you must map the patterns of features with similar values. In order to do this it is essential to know the types of features you are mapping, and again, the purpose of your map so that you can present the patterns.The types of features that you can map are discrete features, continuous phenomena, or data summarized by area. The discrete features are individual locations, linear features, or areas. Continuous phenomena are areas or a surface of continuous values. Data summarized by area is usually shown through shaping each area based on its value or charts that show the amount of each individual category in each area. I am still somewhat confused about what each of these three features look like in practice. I had a hard time contextualizing the examples the book gave. Quatinies, such as counts or amounts, ratios or ranks, can also help you decide the best way to present data. After ascertaining the quantities you have, you generate classes in order to best show them on the map. The essential part of generating classes is that there exists a trade off between accurately presenting data values and generalizing the values to see patterns on the map. Swinging too far in either direction decreases the accuracy of the map and can shift the impact of the data. I appreciate the example maps which show how different the same data can look based on different class schemes. I remember learning about how the natural breaks, quantile, equal interval, and standard deviation classes are different and alter your map projection. I appreciated reading about these and learning more about how they work. I feel like the “making a map” and “choosing a map type” will be more easily understood if I have a map of my own that I am trying to make and can more easily compare the different options to. Currently it is somewhat difficult for me to get through all that information without a baseline map to compare the different options to.
Chapter 4:
Chapter four focuses on how mapping density can elevate a map and allow you to elevate your maps. A density map allows you to use a uniform aerial unit, like hectares or square miles to measure the number of features and clearly see distribution. This is good for things like the number of people in a census or in a county. I think we did this in the previous GIS class with our state county maps. The two ways you can create a density map are by shading defined areas based on a density value or by creating a density surface. Point or line data is typically mapped using a density surface, which looks kinda like a topographic map with varying bands of intensity. When mapping density by defined area, you can use a dot map to represent the density of individual locations. This doesn’t show the specific density centers, just the individual points. Mapping by density surface, as stated above, allows you to see the density centers. I feel a bit overwhelmed by the math that goes into creating a density surface. Does the GIS do this math or is it something done by hand? I remember doing some very basic math for generating classes for the county data we used in the other class, so I feel like it could go either way. In order to display the density surface you generate, you can use either graduated colors or contours. Each class you pick (from chapter three) will show the graduated colors differently, and therefore change the way the map looks. So it is important to understand what you want to show, and which class illustrates it the best. Using contours is a bit different and does a good job showing rate of change across the surface. If the contours are more closely spaced, this means the rate of change is higher. This one actually looks more like a topographical map with differently spaced lines. In the density surface the lines are blended and not defined.


 One of my academic interests is mycology, so I looked up related GIS applications with fungi and found a study using GIS to assess the distribution of fairy rings. Overall I found the study interesting and I hope to come across more research that uses GIS to study fungi. The picture below was taken from an airplane and includes the fairy rings are identified.
One of my academic interests is mycology, so I looked up related GIS applications with fungi and found a study using GIS to assess the distribution of fairy rings. Overall I found the study interesting and I hope to come across more research that uses GIS to study fungi. The picture below was taken from an airplane and includes the fairy rings are identified.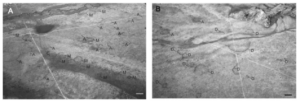
 My name is Evelyn VanderVelde, I am a senior majoring in Environmental Science with a minor in Botany. I hail from Holland, Michigan, and part of Zeeland, Michigan as well (duel households for the win).
My name is Evelyn VanderVelde, I am a senior majoring in Environmental Science with a minor in Botany. I hail from Holland, Michigan, and part of Zeeland, Michigan as well (duel households for the win).