Chapter 7
In chapter seven I started with editing, creating, and deleting polygon features. This was very straightforward and easy to understand. Moving and rotating the polygons to the correct location was actually quite enjoyable. I then used cartography tools to smooth out polygon features and make them look much nicer. I also transformed features with a CAD drawing. I also found this section to be somewhat fun. I am proud to announce that I somehow did not have any problems in this section which has been a first for me so that’s exciting.

Chapter 8
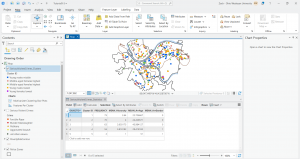
In this chapter I learned a lot about the geocoding process which matches location fields in tabular data. In the first tutorial I geocoded data using zip codes. I built a zip code locator, geocoded data by zip code, rematched data by zip code, and then symbolized using using the collect events tool. This process was pretty quick and simple and I got it done with no issues. In the second tutorial I geocoded street addresses. I messed up the locator tool at first by forgetting a few setting to apply but the second time around I did it correctly. Other than that mistake this also went by pretty quickly.
Chapter 9
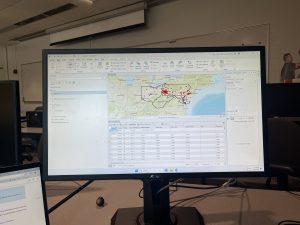
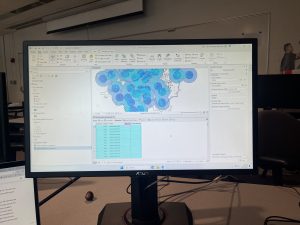
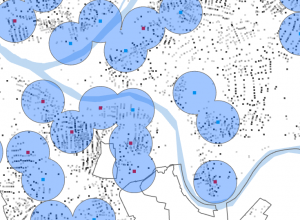
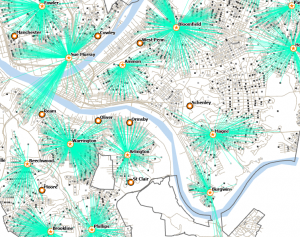
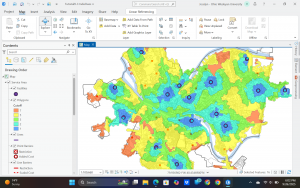
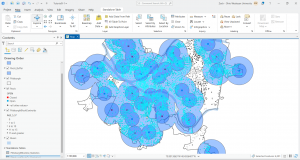
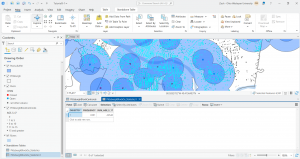
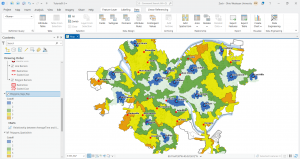
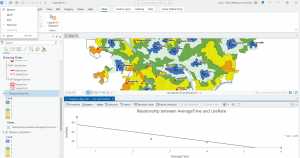
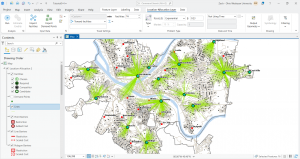
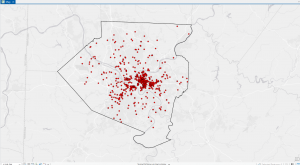
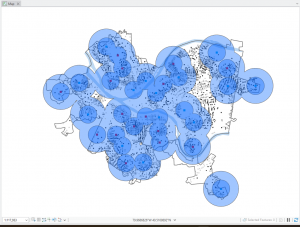
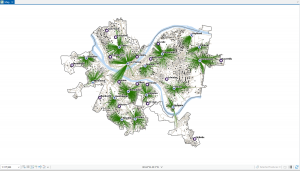
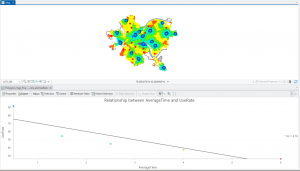
In chapter 9 I started off by learning to use buffers which I really enjoyed. I just like the way they look on the map… I then created multiple-ring service areas for calibrating a gravity model and polygons for them. This was really interesting to see travel time to pools and the colors relating to “quality” like poor or excellent. When it came to using the spatial join tool in this chapter I was struggling at first because I couldn’t find the output fields and merge rule but I think I figured it out by just clicking the specific output field and then finding a sum button. I’m not sure if that was correct but I did it anyway. I also optimally located facilities using ArcGIS Network Analyst and performed cluster analysis to explore multidimensional data. This chapter took a bit longer because of some small random problems but I got it all figured out.
Work I was supposed to start last week for Final
Zip Code- Contains all zip codes within Delaware county
Street centerline- The center of pavement of public and private roads within Delaware county. It was developed from data collected by field observation of existing address locations and by adding addresses using building permit information.
Recorded Document- points that represent recorded documents in the Delaware County Recorder’s Plat Books, Cabinet/Slides and Instruments Records which are not represented by subdivision plats that are active. (vacations, subdivisions, centerline surveys, surveys, annexations, and miscellaneous documents within Delaware County, Ohio)
Survey- a shape file of a point coverage that represents surveys of land within Delaware County, Ohio.
GPS- This dataset identifes all GPS monuments that were established in 1991 and 1997. This dataset updated on an as-needed basis, and is published monthly.
Parcel- consists of polygons that represent all cadastral parcel lines within Delaware County, Ohio.
Subdivision- consists of all subdivisions and condos recorded in the Delaware County Recorder’s office. This dataset is updated on a daily basis and is published monthly.
School Districts- all School Districts within Delaware County, Ohio.
Tax Districts- consists of all tax districts within Delaware County, Ohio. The data is defined by the Delaware County Auditor’s Real Estate Office.
Township- consists of 19 different townships that make up Delaware County, Ohio. This dataset is updated on an as-needed basis and is published monthly.
Annexation- contains Delaware County’s annexations and conforming boundaries from 1853 to present.
Address Point- a spatially accurate representation of all certified addresses within Delaware County Ohio.
PLSS-consists of all the Public Land Survey System (PLSS) polygons in both the US Military and the Virginia Military Survey Districts of Delaware County.
Condo- consists of all condominium polygons within Delaware County, Ohio that have been recorded with the Delaware County Recorders Office.
Farm Lot- consists of all the farmlots in both the US Military and the Virginia Military Survey Districts of Delaware County.
Precincts- consists of Voting Precincts within Delaware County, Ohio.
Building Outline 2023- all it says it building outline 2023
Delaware County E911 Data- For some reason this summary had the same summary as Address points and I dont think thats right.
Original Township-consists of the original boundaries of the townships in Delaware County, Ohio before tax district changes affected their shapes.
Building Outline 2021- consists of building outlines for all structures in Delaware County, Ohio. The layer was updated in 2021.
Dedicated ROW- consists of all lines that are designated Right-of-Way within Delaware County, Ohio. This data is line data that is created through the daily updates of Delaware County’s Parcel data.
Map Sheets- consists of all map sheets within Delaware County, Ohio
Hydrology- consists of all major waterways within Delaware County, Ohio. This data was enhanced in 2018 with LIDAR based data.
ROW- consists of all lines that are designated Right-of-Way within Delaware County, Ohio. This data is line data that is created through the daily updates of Delaware County’s Parcel data.
Address Points DXF- a spatially accurate placement of addresses within a given parcel in Delaware County.
2024 Ariel Imagery- 2024 3in Aerial Imagery. Flown Spring 2024.
Delaware County Contours- 2018 Two Foot Contours
2022 Leaf-On Imagery (SID file)- 2022 Imagery 12in Resolution
Here is my ArcGis Pro project with the Parcel, Street Centerline, and Hydrology layers. Okay so never mind I can’t find the screenshot on my hard drive but I did it and it was very purple.
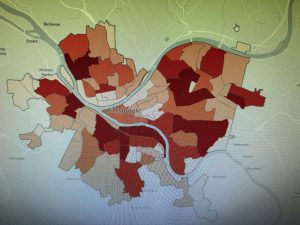
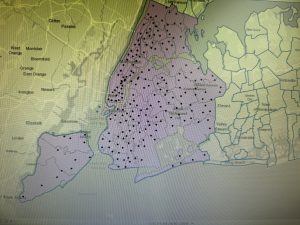
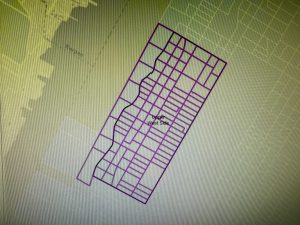
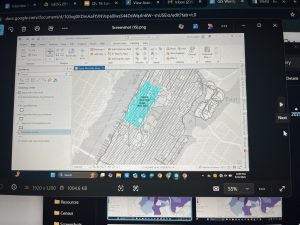
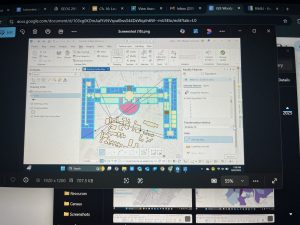
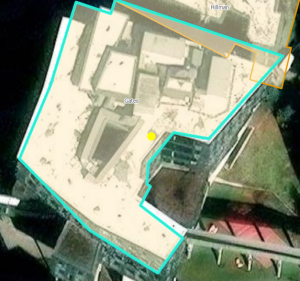
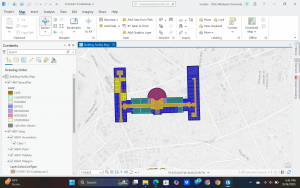
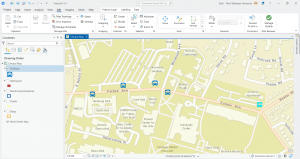
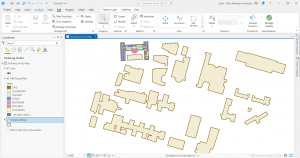
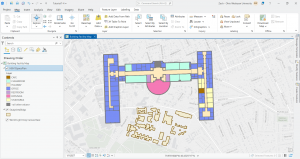
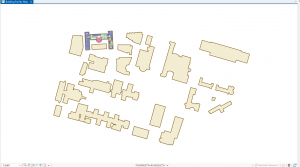
 Chapter 7: This chapter briefly went over how to modify and edit maps. While this chapter didn’t provide super important information, it was still very helpful. It gave me background on how to scale and move polygons within the map. Essentially, this chapter helped me design my maps to be more visually appealing. I only ran into a few problems within this chapter. One of them is my inability to split the buildings. I drew my shape around the building and double-clicked as instructed, but the two buildings in 7-1 didn’t split. It was interesting to apply polygons to not just buildings, but parking lots, and other features as well. This taught me how useful creating a digital version of it on the map can be. Another issue that I ran into was my inability to find the bus stop marker. I don’t think this is a big problem at all because I was able to use another symbol to mark the bus stop, but I thought I would note it. For future reference, it was good to learn that I have to import features from a downloaded building so that I can modify them.
Chapter 7: This chapter briefly went over how to modify and edit maps. While this chapter didn’t provide super important information, it was still very helpful. It gave me background on how to scale and move polygons within the map. Essentially, this chapter helped me design my maps to be more visually appealing. I only ran into a few problems within this chapter. One of them is my inability to split the buildings. I drew my shape around the building and double-clicked as instructed, but the two buildings in 7-1 didn’t split. It was interesting to apply polygons to not just buildings, but parking lots, and other features as well. This taught me how useful creating a digital version of it on the map can be. Another issue that I ran into was my inability to find the bus stop marker. I don’t think this is a big problem at all because I was able to use another symbol to mark the bus stop, but I thought I would note it. For future reference, it was good to learn that I have to import features from a downloaded building so that I can modify them.