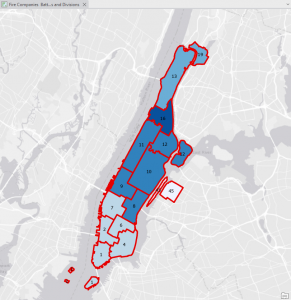
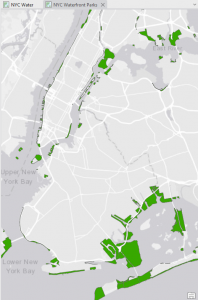
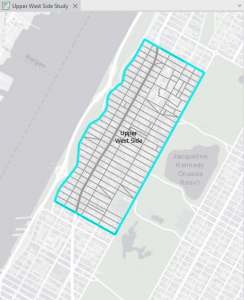
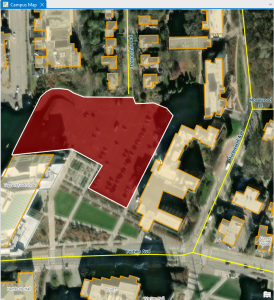
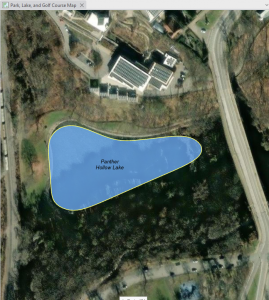
Chapter 1: Introducing GIS Analysis
This chapter begins with an overview of GIS analysis and its crucial role in understanding different geographic patterns. Since this is an introductory chapter, many concepts are introduced. GIS Analysis is the most prominent term introduced, and it explains how GIS is used to analyze spatial relationships and patterns in geographic information. He also introduces spatial patterns, which are the layout of shapes and features in a space, and spatial relationships, which are how certain geographic features interact with each other. These techniques significantly impact decision-making, as they can help us visualize certain things and significantly influence our choices. Another set of terms this chapter goes over are different types of data. I was interested in this concept because they can all be used differently for other purposes and data sets. For instance, point data can represent specific locations, such as cities or landmarks, while line data can represent linear features like roads or rivers. The different data vector points (points, lines, and polygons) help to show specific features or regions, while raster data (grid-based) helps to show a surface and how it changes. Vector points were what I associated with GIS, but it was interesting to learn about raster data since I hadn’t thought of the different types of data that a person could input. The attributes linked to data were also interesting to me, and they are used to help us and the computer understand the data better. The steps outlined in this chapter for GIS analysis reminded me much of the scientific method, with the various steps of testing, retesting, and analyzing while looking at an issue from multiple angles. The most significant takeaway from this chapter is the pivotal role of GIS analysis in decision-making, as it can help us visualize certain things and significantly impact our choices, thereby underlining its importance and influence. Statistics, a crucial component of GIS analysis, provide the tools to quantify and analyze patterns in spatial data, making them an indispensable part of the process.
Chapter 2: Mapping Where Things Are
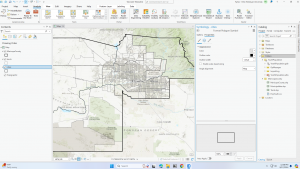
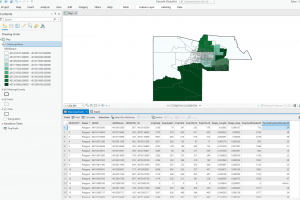
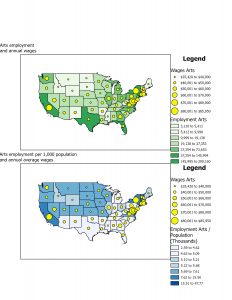
This chapter also places a strong emphasis on statistics, highlighting that a robust understanding of statistics is instrumental in interpreting spatial data. Statistics play a pivotal role in GIS analysis, providing the tools to quantify and analyze patterns in spatial data. One of the significant terms in this chapter is spatial statistics, which applies statistical techniques to spatial data to quantify and analyze patterns. The next term is descriptive statistics, which are just basic statistics. These include mean, the average of a set of data; median, the middle value in a set of ordered data; and standard deviation, the distance from the mean that a large percentage of the data is. This can help compare outliers and find where similar values are located. The chapter also highlights the process of creating a map. In making a map, the person will provide each location’s coordinates and a category value. Then, the person must specify how they want the information displayed. Too many categories can be overwhelming, while too few will show some patterns and can leave out specific details. Visual information and statistical information can be used to locate these patterns. The most significant part of mapping is deciding what, where, and how to map things. Using the correct map is essential because if not, the data can be confusing and lead to misleading results. Just like when writing, the audience is significant as well. The map could be more complex if you have scientists with a lot of background information. If the map is intended for the general public, it must be more straightforward and contain more information to give context.
Chapter 3: Mapping the Most and Least
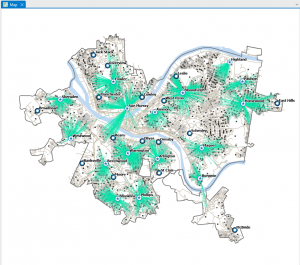
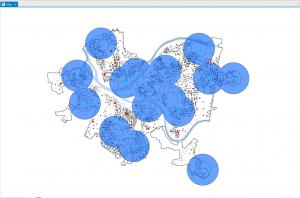
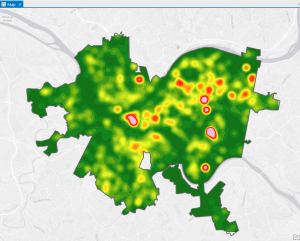
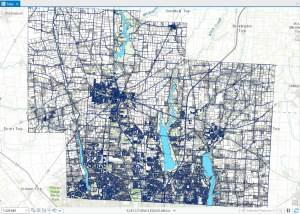
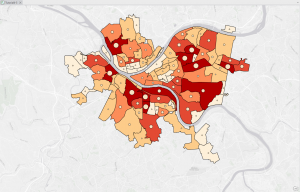
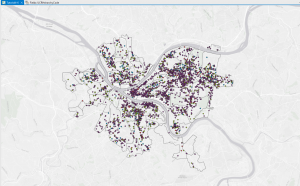
This chapter, which focuses on techniques for analyzing patterns, introduces the concept of spatial pattern analysis. This technique examines geographic arrangements to find patterns, enhancing our understanding of the distribution of certain items and the factors influencing them. Visualization plays a key role in this process, as it allows us to see high- and low-density points. When mapping, three different quantities of features will be given: discreet features, like locations or regions; continuous phenomena that show a constant value in 3D; and data summarized by area, which separates areas through shading, usually with a gradient of colors or contours. When creating maps, it is essential to use specific analysis techniques to give appropriate and helpful results. After being given a quantity, values can be given a symbol to make the map more visually appealing and understandable. This visualization aspect is so important to help see patterns, but if that isn’t enough, statistics can also be looked at. Classes can be added to separate higher and lower values, making the map more understandable. Classification schemes are used to create classes. I like having black-and-white categories because I tend to overthink things in grey areas and which category they should go in. I found these common schemes very helpful: quantile, equal interval, standard deviation, and natural breaks. For quantile, the number of features in each class is the same. The space between high and low values is equal for each class in equal intervals. In standard deviation, the classes are based on how far away from the mean they are. Lastly, in natural breaks, the classes are created based on groups in the data, close values. Overall, the type of map used is essential, and choosing an excellent way to analyze the data can make finding patterns tenfold easier. Selecting a map or analysis method that is less effective can lead to a lack of finding a pattern, which could have lots of impacts on society.