Aslam Week 7 (emailed this before)
Final Project Data Summary
- Tax District
This data set contains all the tax districts within Delaware County. The Auditor’s Office establishes these districts based on tax codes, and this data set is updated whenever necessary. It is published monthly.
- Parcel
This dataset includes all parcel boundaries in the County. The information in this dataset is updated daily by the Auditor’s GIS Office. The information is subject to change as recorded documents are filed.The information on parcels, such as owners and appraisals, is kept using the CAMA system.
- Address Point
These are official LBRS address points, which are centroids of buildings. They are used for reporting accidents, 911 calls, geocoding, among other uses. This information is updated daily by the Auditor’s GIS Office.
- Recorded Document
This data set comprises all recorded documents that do not include active subdivision plans, such as annexations, vacations, centerline changes, and surveys. This data set is used to locate these recorded documents; updates are done on a weekly basis.
- Zip Code
This data set comprises all the zip codes found in Delaware County.This information was cleaned up in the early 2000s, and this data set was created by dissolving parcels based on addresses. It is updated when changes occur within the USPS.
- School District
This data set shows the school districts within Delaware County. This information was created based on parcel information and is updated whenever changes occur.
- Map Sheet
This data set contains all the map sheets within Delaware County. It is essentially the index grid used to create maps within the County.
- PLSS
This dataset includes all PLSS polygons for U.S. Military and Virginia Military Survey Districts. It helps identify these survey districts. It is updated as new survey work is recorded.
- MSAG
At this level, the Master Street Address Guide is added, wherein the boundaries of the 28 political jurisdictions such as townships, cities, and villages are presented.
- Municipality
In this dataset, the map indicating the incorporated municipalities such as cities and villages in Delaware County is added.
- Farm Lot
The boundaries of the farmlots in the U.S. Military and Virginia Military Districts, old boundaries included, are presented in this level of the dataset if updated.
- Township
This dataset includes all 19 townships in Delaware County, updated as the boundaries are changed.
- Street Centerline
This layer includes the LBRS Street Centerline layer, showing the center of the pavement of all the roads in Delaware County, where the address ranges were created through field checks.
- Annexation
This dataset includes all annexations recorded in Delaware County since 1853.
- Condo
This dataset includes the boundaries of all the condos in Delaware County, obtained from the Recorder’s Office.
- Subdivision
This dataset shows the boundaries of all the subdivisions and condos, obtained from the Recorder’s Office.
- Survey
This dataset includes a point layer showing the locations of the surveys, obtained from the Recorder’s Office and the Map Department.The survey documents have been scanned and linked. It updates daily.
- Dedicated ROW
This dataset shows all right of way lines in the county. These are from daily parcel updates and show land set aside for roadways and public access.
- Building Outline 2024
This is the building outline dataset for 2024. It shows all building footprints as they are currently in the most recent imagery.
- Building Outline 2023
Similar to above, this dataset shows building outlines from 2023.
- Railroads
This dataset shows railroad locations in Delaware County. It allows users to view where railroad tracks are in the county.
- Precincts
This dataset maps all precincts in Delaware County. It is maintained in conjunction with the Board of Elections and is updated as precinct boundaries are changed.
- Delaware County E911 Data
Another LBRS dataset for address points, this one is specifically for emergency response. It is used for 911 response and phase II. It updates daily.
- Building Outline 2021
Building outlines from 2021. Useful for viewing older building footprints.
- Hydrology
This dataset shows all major waterways in Delaware County. It was updated in 2018 using LiDAR. It also includes other water features.
- GPS
This dataset lists all GPS monuments established in 1991 and 1997. These are used for surveying and accuracy.
- Delaware County Contours
This dataset contains all 2-foot contour lines. It was made from 2018 elevation data.
- Original Township
This dataset shows original township boundaries before changes from tax districts.
Azizi Week 4
Chapter 1
- In Chapter 1, I worked through several tutorials that introduced the basic tools and concepts of ArcGIS Pro. At first, it took some time to locate certain features, and I felt a bit confused in the beginning. However, as I continued through the tutorials, I gradually became more comfortable navigating the software.
- One concept that stood out to me was how layers are organized on a map. I learned that layers are placed on top of a basemap and that the order of layers is important, because one layer can hide another if it is placed above it. Understanding how to arrange layers correctly is important for making sure the map displays the information clearly.
- In Tutorial 2, I worked with feature classes and practiced zooming to features. It was interesting to see the different types of feature classes and how they are used to represent geographic information.
- Tutorial 3 focused more on attributes and how they can be managed. I learned how to search for, rename, arrange, and select features in the attribute table. I also used the Summary Statistics tool to calculate statistics for attribute values.
- In Tutorial 4, I learned how to change labels, such as those for municipalities, and how to modify symbols using the symbology tools. I also practiced adding and removing feature classes. One of the most interesting parts of this chapter for me was working with a 3D map for the first time and seeing how spatial data can be visualized in three dimensions.
Chapter 2
- In Chapter 2, I learned more about symbolizing maps using qualitative attributes, labeling features, and configuring pop-ups. It was interesting to see how ArcGIS can use attribute values to automatically symbolize different features on a map. I also learned how to create definition queries to show only a subset of features from a dataset, which was very helpful when focusing on specific information. I also practiced symbolizing maps in the exercises, which helped me understand how attributes control how features appear on a map.
- Another thing I worked on was setting visibility ranges for labels. This was mostly about understanding map scales and how the scale of a map relates to real-life distances and areas. I learned how labels and features can appear or disappear depending on the zoom level you choose. This helps keep the map clear and prevents too many features from appearing at once.
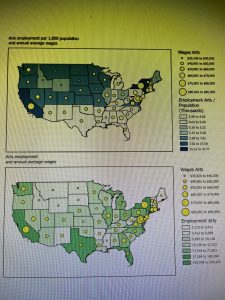
- I also learned about different ways to symbolize quantitative data, such as using graduated symbols or proportional symbols to represent differences in values. This makes it easier to see patterns and comparisons across the map. Another interesting concept was dot density maps, which help visualize how certain quantities are distributed across an area.
- Overall, Chapter 2 focuses more on map design and how to make thematic maps clearer and easier to understand. It shows how the choice of symbols, labels, and scales can help highlight the main subject of the map while keeping other information in the background.
 .
. 
Chapter 3
- In this chapter, I learned how to build map layouts that can include more than one map. It was interesting to see how layouts are designed for reports, presentations, or websites, and how guidelines help place maps and other elements neatly and precisely on the page.
- I also learned how to share maps from ArcGIS Pro by publishing them to ArcGIS Online as web maps. It was interesting to see how maps created in ArcGIS Pro can be used online and then edited further in the ArcGIS Online Map Viewer.
- I created a dashboard using ArcGIS Dashboards and displayed spatial data more interactively. The dashboard had a map, tables, and charts that updated dynamically based on the area shown on the map. It was interesting to see how this type of tool can help organizations monitor service requests and make decisions more efficiently.
- While working with the dashboard tutorial, I explored different tools like bookmarks, basemaps, and layers. I was also supposed to find the “Expand” button on the top right corner of the map to enlarge it, but I honestly could not locate it, so I continued exploring the map using the other available tools.
 .
. 
Butte_Weeks 6-7
Week 6 Work:
Chapter 7:
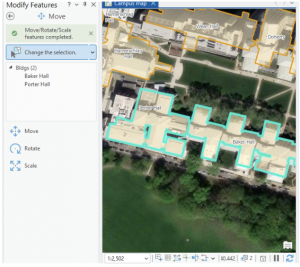
This chapter/ tutorial was actually a lot of fun to work with. It felt a lot like working in Adobe Illustrator, with making the point lines, and moving the features. I also felt very fancy using the Cartography tool, and “improving the aesthetic” of my map/ its lines. Learning how to edit, delete and move the buildings around was super cool. This is extra useful in the world we live in today, with construction and deconstruction always affecting/ moving locations and landmarks. It was interesting to think that no matter how “good” a map might be, there can still be aspects of it that are warped between the system and ground map. Being able to fix that distortion can be an extremely invaluable tool. Creating features is also very useful when starting a map from scratch, or if the project doesn’t include the needed feature class. Because this chapter dealt with a lot of permanent modifications, it included good advice to keep an unedited version of whatever map you’re working on in case of any errors. That way you can just go back to the original file and start the map over again. Using a style of system work that mimics the work of Architects and professional location planners at the end made the assignment feel very professional. Like, it ran us through what the professionals do, giving us an idea of what to expect if any of us wish to go to that level.
Chapter 8:
This chapter went very local, working primarily with Zip Codes and Counties. Using geocoding to map the charts of zip codes and counties, the chapter bridged the gap between chart data and actual geographic locations, inputting them into analyzable features on the maps. This chapter introduced Match Scores, something that I am still trying to understand a little bit more. Essentially, the match score shows the percentage of accuracy of an address when evaluated with a reference. Around 85%-98% is usually an acceptable score range, but in some situations it’s ideal to try to have a perfect 100% match. I did have a few issues with this chapter when trying to Rematch Addresses. Whenever I would try to click the map to set the rematch, I would continue to get pop-ups and the rematch selection wouldn’t actually register. I turned off the pop-up setting from the map (temporarily) and it seemed to bypass the issue. As I stated before, I believe that longer tutorials are more beneficial to my learning process- and this was heightened using chapter 8. As this chapter only actually has 2 assignments built into it, they both build off of every step followed in the textbook. If something was missed, or incorrectly done, the entire assignment would be messed up and needed to be redone. This was a bit annoying, but in the end the repetition definitely aided my understanding of the topics taught in this chapter.
Chapter 9:
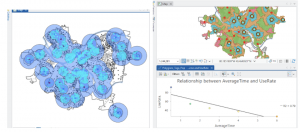
Learning about and setting up buffers was something that was briefly recapped in some of the much earlier chapters, so I had some initial knowledge on them. My first thought when working with them was that they’re bubble letters for feature plots! These bubbles were quite fun to set up, and I can visualize a lot of reasons why someone would use them on a map- like finding a specific feature within a distance from certain features, and gathering data on what’s outside these zones as well. It’s very neat that the buffers can have multiple layers of distances applied to a single feature set at the same time. And although I actually like the “target” look on the map, and how it visibly shows the change in distance on the plot, I can understand that there might be reasons to make a single “multiple ring” buffer containing both blended together. A small note for the future, that using Optimized seed in the Multivariate Clustering tool is the setting that should be used when making your own projects/ data. This entire chapter was extra visually appealing for some reason, the colors used as symbology on the features fit well, and I absolutely love the way the map looks with the Locations-Allocation assignment with the lines diverging from the “ideal” location points. That entire assignment was fascinating as well, how the system was able to calculate the best locations of pools from the data collected and accessed. It was a great representation of the ability of GIS to manipulate datasets to create purpose driven maps. The system works for real world problems, using analysis to work out relationships between features/ points, and provide a simple answer to questions asked about data.
Week 7 Work:
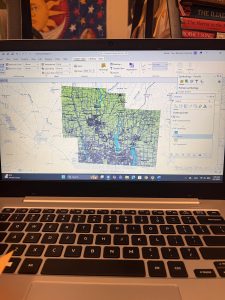
The Delaware City maps have been downloaded, and inserted onto a created GIS Pro map for the final project map. I moved the maps around adjusting their map display from the drawing order to see which layering was best, featuring all the needed datasets. The Parcel map is very interesting to explore, with how much detail it has within its data and display. I generated ideas for my final project and evaluated each dataset’s information.
The Parcel map is managed daily by the Delaware County’s Auditor GIS Office, with data kept by the Delaware County Recorder’s Office. It shows clearly defined boundaries of land plots and features from all around Delaware. It is packed to the brim with every single road, building and section of land, complete with their IDs, data, and building names. I will note that the map looks like it could be a little bit off, with some features not in the correct location on the map, or it could simply be the way I have it layed out creating this illusion. This dataset is key to working on the “What’s Inside?” section of the final project, as it requires the data being gathered to be set from within, or inside a parcel of Delaware land.
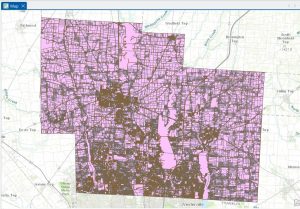
The Hydrology map shows all major waterways of the Delaware County, and was made in July of 2022 with no updates since then. This dataset could be useful if inspired to work with runoff into waterways, or a specific project with water. However, it may not be entirely useful for other areas of mapping besides acting as a location identifier.
The Street Centerline map is a highly adaptable map with many ways to use it and displays exactly what it sounds like, all the public and private roads located within the Delaware County district. Made from data collected by The State of Ohio Location Based Response System (LBRS), the map remains updated daily for most aspects except for the monthly 3-D model updates. This map is great for landmarking, and making the map easy to understand if reading it for specific locations. This map can be useful for a number of things ranging from emergency response maps and ranges, to appraisals and accident reports.
Ramirez Week 7
PLSS: This data is called the public land survey systems where all the public land is visible in Delaware county. This data is useful for both U.S and Virginia military districts and it is updated monthly.
Zip Code: This data set contains all the zip codes in Delaware county. Some of the zip codes were manually created because they did not automatically appear on the system. They also used U.S postal service and other sources to gain the information. This map is also updated monthly.
School District: This dataset contains all school districts within Delaware County. The data comes from the Delaware County school district records. It is updated and published monthly.
Township: Includes information of 19 different townships in Delaware County. It is also updated when needed and published monthly.
Delaware County E911 Data: This data includes information on all certified addresses within Delaware County. It contains information regarding 911 agency information to improve their services. It is also updated when necessary and published monthly.
Building outline 2021: Data consists of all building outlines in Delaware county. The most recent update was in 2021 but it is updated as needed.
Original Township: I couldn’t find any information regarding this dataset.
Recorded Document: This includes points which represent recorded documents in Delaware county’s Recorder’s Plat Books. This is helpful when it comes to locating specific documents that may be scattered throughout the county. This is updated weekly and published monthly.
Building Outline: I couldn’t find any information about this dataset.
Dedicated ROW: Represents all the Right-of-Way paths in Delaware county. Information was gathered from Delaware’s County Parcel data. This is updated daily and published monthly.
Building Outline 2023: Shows all the building outlines in Delaware county from 2023.
Precincts: Included information about voting Precincts in Delaware county. Information was gathered using Delaware County Auditor’s GIS from the Delaware County election board. It is updated when needed and is published when needed by the election board.
Delaware County Contours: It looks like the data is from 2018 and it shows the Two Foot Contours for Delaware County.
Street Centerline: Includes data on paved public and private roads within Delaware county. It is used to support road safety and improve 911 services, as well as ensuring the roads are up to date. It looks like it is updated annually but the data is published monthly
Condo: Includes data of all condos within Delaware county.
Parcel: Includes data on all registered parcel lines in Delaware County. The data was collected through the Delaware County Auditor’s GIS office. It is monitored daily and is published monthly
Subdivision: Includes data of all subdivisions and condos from the Delaware County recorder’s office. It is updated daily and published monthly.
Tax District: Includes information of all tax districts in Delaware county. The data is recorded on the Tax district code. It is updated as needed and published monthly.
Address point: This includes information of all registered addresses in Delaware county. It helps 911 agencies to find the most suitable places for their job. It is updated daily and published monthly.
Map sheet: I could not find any information about this set.
Hydrology: includes all major waterways in Delaware county. Information was gathered and updated using the LIDAR enhanced dataset in 2018. It is updated as needed and published monthly.
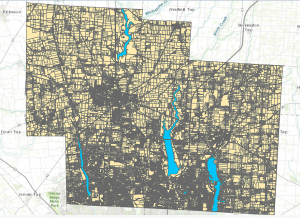
Week 7- Spurling
This week I basically just downloaded all the data needed for my final project. I explored the Delaware County, Ohio GIS Data Hub and looked through the datasets available in the “All Files” section. I downloaded Parcel, Street Centerline, Hydrology, and Township Boundary shapefiles. I also extracted them and exported them to ArcGIS. In terms of what they each do: Parcel outlines property boundaries across the county, Street Centerline layer displays the county’s road system, and Hydrology layer identifies streams and other water features. For my final project I also had to download the subdivision shapefile because I decided to do”Mapping Change” as well as “Making New Shape Files from Existing Shape Files”.
Cherry Week 7
Zip code:Contains all the Zip codes in Delaware County, Ohio. It was made by using data from the Census Bureau and the US Postal Service from 2000 and was created in 2005. It is not regularly updated but is updated on a when-needed basis, using the US Postal Service, which is updated monthly.
School District: This holds data that pertains to all schools within Delaware County, and is updated on a as needed basis, and issues the data from Delaware County Auditor’s parcel records to create it.
2021 Imagery: Imagery that was captured in 2022 and last updated then as well.
2022 Leaf-on Imagery: Imagery created in 2022 that has a different resolution of 12in
2024 Aerial imagery: data that was obtained during the spring of 2024 and contains 3in an aerial view.
Address Point: Locates the individual building location as accurately as possible while using data from The State of Ohio Location Based Response System and through a partnership between The State of Ohio and Delaware County.
Annexation: This contains information about conforming boundaries and annexations from and that date all the way back to 1853.
Building Outlines DXF + Building Outline 2021 + Building Outline 2023:The DXF uses CAD drawings and was last updated in 2020, while 2021 and 2023 are new updates. The building outlines that were updated in two years after their respective names,while being service features files.
Condo: This data consists of condominium polygons that assess and give a view to the individual units within a condo. This uses data from the Delaware County Records Office and was last updated a few days ago 2/27/2026
Dedicated ROW: Shows all Roads within Delaware County that consist of Right-of-ways, It is updated on a daily basis and published updates once a month and it was published in 2020
Delaware County Contours:A geodatabase file last updated in 2021 that shows the ‘contours’ of delaware county that is basically showing the terrain, the elevation etc.
Delaware county E911 Data:Uses data and address points to locate the centroids of buildings, which is important for emergency services. It was also published in 2021 but is also updated daily and published on a monthly basis.
Farm lot:This was built with the intention of showing military farmlots in Delaware County. It is updated on an as needed basis whenever new surveys are done on these areas. It was 2020 and was last updated in February of this year.
GPS +Delaware County GIS Data Extract Web Map:Identifies monuments from 1991 – 97 and is updated on an as needed basis. Also hasn’t been updated since 2021.
The extract web map of Delaware County in GIS that is able to be extracted into a variety of formats.
Hydrology: This data set shows the major ‘water ways’ within the Delaware County Region, also updated on an as needed basis.
Fall Background: A background for fall that was created in 2019 and last updated then as well.
MSAG:A master street address guide that depicts the different political jurisdictions.
Map Sheet: All map sheets within Delaware county. Created in 2020 but most recently updated in February.
Municipality:Pretty self-explanatory it is basically data that consists of all the municipalities within Delaware County. Created in 2020 and last updated in February as well.
Original Township + Township: The original township lines of Delaware County before tax districts changed these lines. Township consists of the 19 different townships that makeup the entirety of Delaware county.
Parcel:Parcels are polygons that represent all cadastral parcels which are
Precincts: Shows the division between the voting precincts in Delaware County.
Railroads: Shows a view of all railroads within the Delaware County lines.
Recorded Document:A sum of miscellaneous recorded documents in relation to Delaware county. It is updated on a weekly basis.
Street Centerline + DXF Centerlines:This uses LBRS to depict pavement centers of public and private roads with intentions to support appraisal mapping and emergency response services. DXF Uses field surveys
Subdivision: This data contains information in regards to all recorded subdivisions and condos in Delaware county.
Survey:These are survey points that represent shapefiles of surveys of the land. Old volumes are not currently included in this.
Tax District:Includes all and separates the tax differences within Delaware County. It was published in 2020 and recently updated last month on an as needed basis
Butte_Week 5
Chapter 4:
Chapter 4 gets into the databases/ Geodatabases. A very helpful thing to understand when working within ArcGIS- they are the central storage bank for all information/ data that pertains to a certain organization or project. File geodatabases have no limits to the size or amount of feature classes or raster datasets could be stored in it, and it keeps all your project information in one easy to access place! Over the course of the next few chapters, I used the geodatabase for each chapter to select any files I needed, quickly. It’s good to learn how to convert external files into the proper format for the file geodatabase, so you know how to work on a map from an external source. This is primarily because when working on a project from scratch, a lot of the data needed might not be available from the Esri/ ArcGIS collections, and would prompt the need for an outside source (like a census bureau tract for example). There was a bit of bookkeeping this chapter, with moving files around and developing understanding of these databases. One thing I learned that I found very helpful was that if you delete something from the contents pane, it is still filed in the geodatabase and can be brought back to the map. While on the other hand, if something is deleted straight from the database, that is permanent. As someone who is very nervous when deleting anything on a project, understanding how the files work within their environment and where backups are is good knowledge to have! I also liked that the system won’t let you accidentally delete any important keys from the field table. This is very reassuring as working with the tables can get somewhat confusing, and I’m always worried I’ll hit a button and accidentally erase a needed field. It was also interesting to learn that GEOID and GEOIDNumber are technically the same data, but two different ways that the field can be categorized. While they are the same kind of attribute, they cannot be joined together due to their different codes (GEOIDNum- 4048 vs GEOID- 04870). Diving deeper into the Python language and SQL helps me develop a stronger understanding of what I am doing when adjusting the code on my map. Like understanding that using ‘OR’ within a data query is essentially saying and/ adding the two fields instead of using one or the other like it sounds- and using ‘AND’ means the opposite, picking one or the other. Using the SQL and Definition Query to plot out exact pockets of dates and times to find the specific data you’re looking for is especially important when you need a small time pocket of data from a larger scaled data set.
Chapter 5:
This chapter felt like we were learning how to read a map the “old-school” way, developing skills on reading and understanding the longitude and latitude, and positioning of locations. I appreciated that it explained map proportions and showed that most of the maps we’re taught about in school are technically all distorted/ inaccurate. I learned a new word that I actually quite like: Graticule. In regards to the longitude and latitude, a graticule is the coordinate point system. Chapter 5 gets back into the local versus world aspect of maps, detailing that certain maps work better on a smaller vs. a larger scale. For example, using localized projected coordinates for a smaller map such as Minneapolis or Hennepin works best due to its specialized data that focuses specifically on that region. This chapter also talked more about the file types, with specifics on shapefiles and the continued use of the geodatabase. I also learned how to access other websites to download their maps/ data- like the ArcGIS Living Atlas and dealing with the US Census Bureau again. At the end, I had a few issues when working on the joint data/ choropleth map section. The copied fields had been showing no data, and although I went back and repeated the steps from the start, the fields continued to not provide any data needed to even change the symbology into the graduated scale.
Chapter 6:
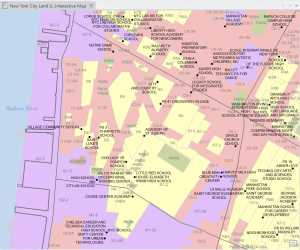
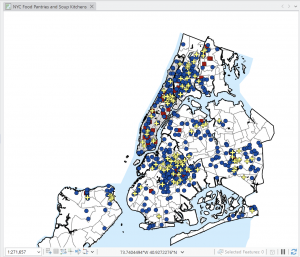
I love how this chapter began with more examples of real-world applications with the GISystem. That it did not abandon the initial idea that Geospatial Analysis tools can be used for many more reasons than people would first assume. On tools, the chapter explores a lot more, various geoprocessing tools. Because there are so many tools within the GIS system, it’s very helpful that the tutorial runs through as much of them as possible. Giving more examples and definitions, and having us actively use and have our own “turn” at using the tools. Intersecting features was surprisingly simple, and although the chapter has a lot of assignments, they were all short and sweet. That being said, I believe I learn better from the longer tutorial assignments, where if something is done wrong at a certain stage, then any work that connects to that could be off as well. It raises the stakes, and makes me pay close attention to what the tutorial says, and what I’m doing in my project. Setting a Study Area was one tutorial that I found particularly useful. When working in a location (like New York City) that has an overwhelming amount of streets and attributes, blocking off a specific work area quiets the noise and makes everything easier to work through. On the topic of simplifying everything, putting all classes into one single feature class really keeps things decluttered and simple- definitely something I will take advantage of in the future. This chapter really showed how many different ways there are to combine features, maps and tables (like the Union tool, or Intersect tool).
whitfield Week 7 (pt. 2)
I completely forgot to include this in my first week 7 post, so I made a part 2: