Hello everyone! I am Alyssa Gregory and I come from northeast Ohio, around the Youngstown area. This is my first year here at OWU, though I am actually a sophomore. My major is a B.S in Zoology and a minor in Environmental Science. A little more about me is I love everything outdoors – going on hikes, drives, and experiencing any weather that comes my way. I am hoping to become a wildlife biologist later in the future, so this course will be of great use to me.

This chapter introduced me to the complexities of GIS. Having no prior knowledge of GIS, this was very shocking – especially considering the fact that GIS is interconnected with almost everything around us in many different ways. The chapter explained how GIS is constantly influencing our decisions about food production, city infrastructure, environmental management, etc.. Since these decisions on GIS are often not made publicly aware, there are some concerns that should be brought up in regards to the political aspect. How much power is actually behind spatial data and who controls this ‘invisible’ power. Is this possible scenario of a corrupt system something us people should look more into? I think this is something I will most definitely research later on in the course once I gain more knowledge about GIS itself. Moving to the explanation of classifications and boundaries with GIS, I found this quite fascinating. I was trying to wrap my head around the idea of natural features and social features having almost no clear edge – which creates a difficulty in translating the real world into technology. The excerpt described how mountains, habitats, and communities do not end at precise lines. GIS forces these variables into rigid categories for the following reasons: funding influences, conservation priorities, land management, and habitat loss. The results of GIS clearly show how they are shaped by not only technology, but also human choices. I am excited to learn more about this perspective of the world. I am someone who cares to see all sides of a story, so taking this class will help me grow that attribute of myself. Since I am going to major in Zoology, having knowledge of GIS and all of its properties will be beneficial because populations and ecosystems are constantly fluctuating. In addition to aiding me in an introduction as to what GIS is, it also provided me with a sense of curiosity and eagerness.
Application 1: Critical Habitat | NOAA Fisheries
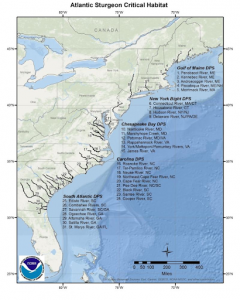
For my first application I decided to research something I am passionate about – endangered animals. I was surprised to find that the main ways GIS is used within the field of endangered animals is GPS tracking and habitat mapping. With concern to habitat mapping, there is a further step when species are listed under the ESA (Endangered Species Act), which is Critical Habitat Designation. A Critical Habitat Designation is a specific area within the geographical area occupied by a species listed under ESA that may require special management considerations or protection. GIS maps out this area and creates Critical Habitat spatial data. I decided to use a map of the Atlantic Sturgeon Critical Habitat, as some of them have been listed under the ESA since 2012.
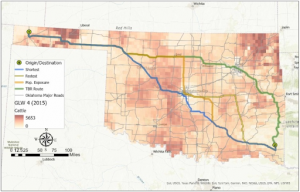
Application 2: A GIS-based framework for routing decisions to reduce livestock disease
As a zoology major I wanted to keep seeing the different GIS applications that are used for animals. An interesting idea that I came upon is still in the works it seems; however, everything is set up, it just needs to be implicated and used. GIS creates maps that contain cattle population densities and route characteristics (exposure to disease, distance, and fastest/shortest) for the reason of transporting livestock, cattle specifically.
Lastly, I completed the GEOG 291 Quiz!