Chapter 1 Tutorial Reflection
Chapter 1 was my introduction to ArcGIS Pro, and at first it felt overwhelming due to the number of tools, panels, and data layers involved. I initially struggled with navigating the interface and locating the correct tutorial files, but after rereading the instructions and becoming more familiar with the project structure, the process became much clearer. Once I understood how projects, maps, and data are organized, the software felt far more manageable.
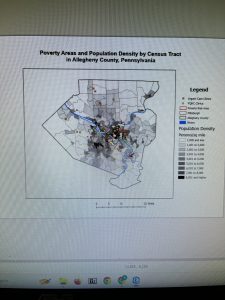
This chapter helped me understand that GIS is more than just map creation—it is a way to organize, analyze, and visualize spatial data. Learning about feature classes, raster datasets, file geodatabases, and projects gave me a better understanding of how environmental data is stored and accessed. Being able to view attribute tables alongside spatial data reinforced the idea that GIS links environmental information, such as land cover or population data, directly to geographic locations.
From an environmental science perspective, these skills are especially important because many environmental problems are spatial in nature. For example, understanding where pollution sources are located, how land use changes over time, or where vulnerable ecosystems exist requires accurate spatial organization of data. The ability to turn layers on and off, switch basemaps, and use bookmarks can help environmental scientists focus on specific regions or environmental factors.
By the end of this chapter, I felt much more confident using ArcGIS Pro and less intimidated by the software. This chapter provided a strong foundation that I can build on in future environmental science coursework and research.
Chapter 2 Tutorial Reflection
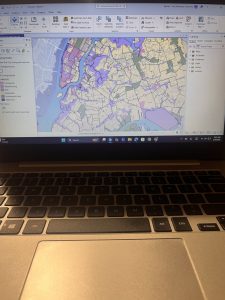
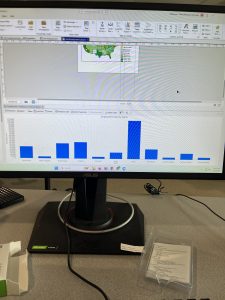
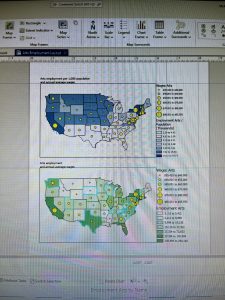
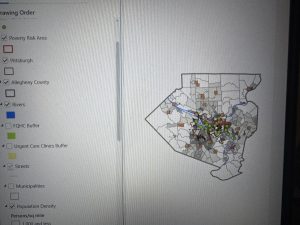
Chapter 2 focused on creating thematic maps and working with symbology, which made GIS feel more creative and analytical at the same time. Using zoning and land-use data helped demonstrate how GIS can display multiple variables simultaneously and reveal patterns that are not obvious in raw data. I found it interesting to see how different land-use categories were visually represented and how color choices affected interpretation.
This chapter was particularly relevant to environmental science because land use plays a major role in environmental health. Mapping residential, commercial, industrial, and park areas helped me understand how development patterns can impact ecosystems, air and water quality, and access to green spaces. Thematic maps like these could be used to study urban sprawl, habitat fragmentation, or areas at higher risk for environmental pollution.
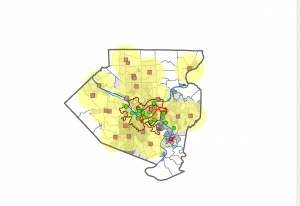
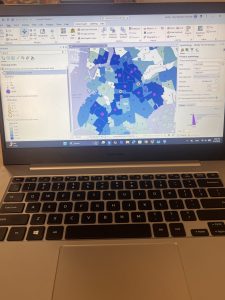
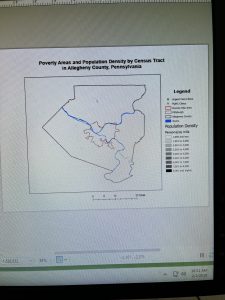
Learning how to create choropleth maps and work with census data also has clear environmental applications, especially when analyzing environmental justice issues. For example, mapping households receiving food assistance alongside environmental risk factors could help identify communities that are more vulnerable to environmental hazards. Definition queries were especially useful because they allow data to be filtered without permanently altering datasets, which is important when comparing environmental conditions across regions.
Overall, Chapter 2 showed how GIS can be used as a powerful visualization and analysis tool in environmental science, helping connect human activity with environmental impacts.
Chapter 3 Tutorial Reflection
Chapter 3 emphasized sharing GIS results with broader audiences, which is a critical skill for environmental science. Environmental data is often used to inform policymakers, researchers, and the public, so learning how to present maps clearly and effectively is extremely important. This chapter focused on layouts, charts, and online sharing tools, which helped translate technical GIS work into accessible formats.
I found the layout and chart creation sections to be challenging at first, particularly when arranging map elements and legends. However, these skills are essential for presenting environmental data in reports, presentations, and publications. Being able to create static maps with map surrounds helps ensure that environmental information is communicated clearly and professionally.
Using ArcGIS Online and ArcGIS Story Maps was especially valuable from an environmental science perspective. Story Maps provide a way to combine maps, text, and visuals to explain complex environmental issues, such as climate change impacts or conservation efforts, to non-experts. This is important for public outreach and environmental advocacy.
Overall, Chapter 3 helped me understand how GIS can bridge the gap between data analysis and real-world environmental decision-making. It reinforced the importance of communication in environmental science and showed how GIS tools can be used to share environmental data in meaningful and accessible ways.
P.S. I wasn’t sure if the photos were supposed to be of the final product or just a part of the process so I just snapped photos when I remembered to.