Chapter 1
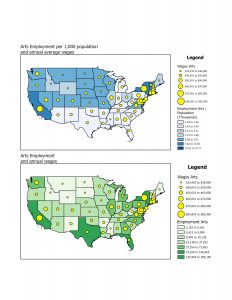
GIS is defined as a “process for looking at geographic patterns in your data and at relationships between features” (Mitchell). All GIS analysis has to start but knowing what information it is you need to gather, so you have to start with a question. Once you have gathered the necessary information you need there are multiple ways to display it such as a map, charts, or a table with values. On the maps there are various geographic features. They are; discrete, continuous phenomena, and summarized by area. Discrete features are features that can be pinpointed. I think personally a better word is definite features, since the feature is either there or it isn’t. Continuous phenomena are features that are identified everywhere such as temperature and precipitation. They are features that have no defined borders, and often start out as sample points for certain areas. Then the GIS will assign values for the in between area (interpolation. This is honestly so cool to me. The idea that it will create a blended feature just sounds like a futuristic thing. Finally summarized by area are features that represent the density or counts of features in boundaries like business profits or population density. In all honesty this one looks the least cool (Hey you asked for comments). Features can be represented in GIS by using two models. The first model is a vector which has each feature in a table and the shapes are defined by “x,y” locations (like a coordinate plane). Vector areas are represented by polygons on the map. The second model is raster. Raster is a matrix of cells in a continuous space. The cell size that’s used for the raster will affect the results of the map. A small cell size will have more cells which leads to more detail, similar to that of a screen. When making GIS layers they should be on the same map projection and coordinate system. This way you avoid issues in distortion between layers. Each feature has one or more attributes that identify what it is or how big it is. The first attribute is ranks, which put features in order from high to low. Ranks are relative, so you only know the order, but you wouldn’t know how much higher or lower the values are from each other. The next two are counts and amounts. Counts show you the actual number of features on a map and amounts are any measurable quantity associated with any feature. And the final attribute is ratios, which show how two quantities are related.
Chapter 2
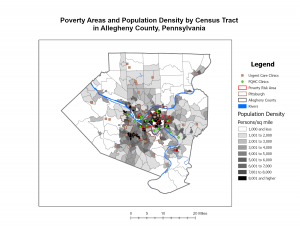
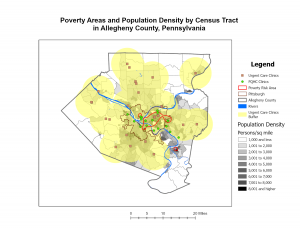
Maps can be used for a lot of different reasons, whether it’s where a feature is or what the feature is. They can also be used to look at the distribution of features. By looking at this you can see patterns that form and they can help you better understand the area you are trying to study or map. Mapping where things are can better show you where you need to focus or where all of your criteria are met. One example that came to my mind was their watershed GIS that was able to articulate which watershed needed to be prioritized. One really important thing to do with GIS is to tailor the map to who you are marketing to. If I was showing a map to the sheriff’s office, I’m not going to include a layer for commercial sales. To me, this seems kind of obvious but at the same time, I wouldn’t have thought about this. The amount of detail also should be tailored, specifically to the format at which you are presenting the data. If you are presenting on a screen during a meeting, small details might not be the best. But, if you are working on a poster that will hang up in a hallway for an extended period of time, you can add many more details. Each feature in GIS needs geographic coordinates. They can be determined by street names or addresses. Also they can be identified by using longitude and latitude. GIS also requires you to have a code for each feature (i.e. robberies). I didn’t really understand why at first, but then it explains that a numbering system could allow your data to be broken down into subsets. The book says you should not use any more than seven categories for a map. However, in my opinion I think five is a better number because it’s less crowded. The book does come with a solution to complicated data sets. The solution is to have separate maps, one with the generalized data and the other with the subset data. I honestly really like this idea because it would allow one map to be simple, then IF you need more specific data you can look in the subset map. GIS can help you recognize patterns such as population density, characteristics, and relative location. However, you have to be careful because being too zoomed in could reveal different patterns than if you were to zoom out. This really reminds me of observer bias. But honestly it made a lot of sense. I really liked this chapter, I found it very interesting.
Chapter 3
When people map the most and least places for their subject. They are able to see the relationship between the areas. This allows more information to be processed. Not to mention, if you only map out the most frequent places for your feature, you’re not collecting any real data because you are not collecting any control. There’s nothing to compare it to. That’s like looking at a map of the U.S and the only feature is “The United States,” what would be the point? In the section “What type of feature are you mapping?” they resay what they say in chapter 1. They talk about the 3 types of features (discrete features, continuous phenomena, or data summarized by area.). They also reinstate that you have to remember who your audience is. This way you are not representing data that doesn’t pertain to the group who is receiving the map. Quantities are also an extremely important part of mapping most and least. They can be; counts, amounts, rations, or ranks. The chapter goes over counts and amounts again, however it does add some advice. Mapping counts and amounts are used in each of the three types of mappings. It can also be helpful to present quantities differently. Sometimes it is better to present exact locations rather than by generalized areas such as area codes. This also goes into proportions, which can show how much of that area represents the whole. This reminds me a lot of things like political maps, when they show who has voted per county. Creating classes for certain features is also a helpful tool. This allows you to see different features more easily. Using different symbols is the best way to do this in my opinion. Sometimes it is best for the classes to be percentages, this is because it would show you the dense areas vs. the not so dense. But sometimes there are outliers in the data that can skew these percentages. With these you should use a number for the classes, which would allow you to add needed breaks.