Final Project Data-
Tax District: Consists of all the tax districts within Delaware County. The data is updated as needed and published monthly. It is defined by the Delaware County Auditor’s Real Estate Office and is dissolved on the Tax District Code.
Parcel: Dataset consists of polygons that represent all cadastral parcel lines within Delaware County. This is maintained by the County Auditor’s GIS Office. Different attributes regarding the parcel records are maintained on the CAMA system on a daily basis and published monthly.
Address Point: This dataset is a spatially accurate representation of addresses within Delaware County. It contains Address_Points that indicate the location of the building centroid. This provides data to help appraisal mapping, 911 Emergency Response, accident reporting. geocoding, and disaster management. It can alter the set of coordinates to determine the closest valid addresses specifically for 911 Emergency Response teams.
Recorded Document: This consists of points that represent recorded documents in the Delaware County Recorder’s Plat Books, Cabinet/Slides and Instrument Records that are not represented by subdivision plats. This dataset was created to locate different documents within Delaware.
Zip Code: This data set contains all zip codes within Delaware County. The zip codes were carefully made and cleaned up in 2003 to later have the layer created in 2005. The layer created both right_zip and left_zip attributes for the county’s road centerline. This is updates as needed through the United States Postal Service.
School District: This dataset contains all the school districts within Delaware County. The data was created by the Delaware County Auditor’s parcel records of the school districts and is updated as needed.
Map Sheet: This dataset contains all the map sheets in Delaware County. It is a feature service and tags Land Data and Boundaries. There was not much more information on this specific file.
PLSS: This data contains PLSS (Public Land Survey System) polygons in the US Military and the Virginia Military Survey Districts of Delaware County. It helps identify all the PLSS and their boundaries.
MSAG: This dataset contains the Master Street Address Guide (MSAG) polygon with 28 different political jurisdictions. These include townships, cities, and the villages in Delaware County. This dataset was made to facilitate and locate each of these places and is updated on an as-needed basis.
Municipality: This dataset was made to consist of all the municipalities within Delaware County.
Farm Lot: This dataset consists of all the farm lots in both the US Military and Virginia Military Survey Districts of Delaware County. The dataset was created to help identify the farm lots and their boundaries.
Township: This dataset is a map of the 19 different townships hat make up Delaware County. This is updated on an as-needed basis and published monthly.
Street Centerline: The LBRS (The State of Ohio Location Based Response System) Street_Centerlines depict the center of pavement of both public and private roads in Delaware. The range data was created by collecting field observation of existing address locations and by adding addresses using building permit information. There are two versions available for download of this data.
Annexation: This dataset contains Delaware County’s annexations and conforming boundaries from 1853 to present. This data set is updated once annexation has been recorded on an as-needed basis.
Condo: This dataset consists of all condominium polygons within Delaware County. These are specific condos that have been recorded with the Delaware County Recorders Office.
Subdivision: This data set consists of all subdivisions and condos recorded in the Delaware County Recorder’s office. This is updated as needed and published monthly.
Survey: Survey points is a shape file of a point coverage that represents surveys of land within Delaware County. Surveys were scanned and kept as pdf filed by the Map Department and the GIS Office in Delaware.
Dedicated ROW: This data consists of all lines that are in the designated Right-of-Way within Delaware County. This data is line data that is created through the daily updates of the Parcel Data. All changes made are stored in the Delaware County Recorder’s Office.
Building Outline 2021/2023/2024: These are two separate datasets, one for each year. These include the building outlines of Delaware County in their designated year.
Railroads: This dataset includes all the railroads that lie within Delaware County and allow viewers to see their location.
Precincts: This dataset includes the Voting Precincts within Delaware county. This dataset is maintained by the Delaware County Auditor’s GIS Office under the direction of the Delaware County Board of Elections.
Delaware County E911 Data: This dataset is the State of Ohio Location Based Response System (LBRS). The Address_Points data set is a representation of all certified addresses in Delaware County.
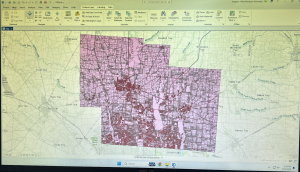
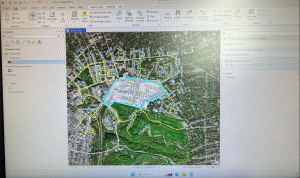
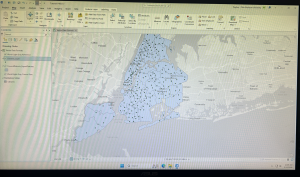
Inserted above is the image of my map after adding the three layers: Parcel, Street Centerline, and Hydrology