Mitchell 4, 5, 6
Ch. 4
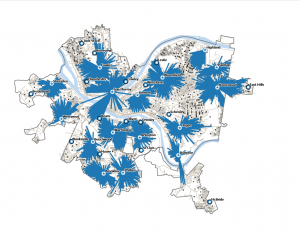
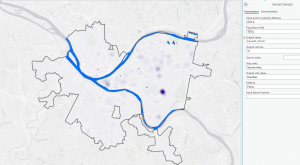
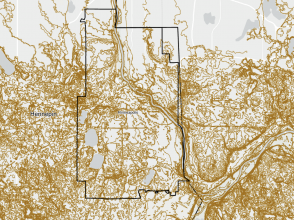
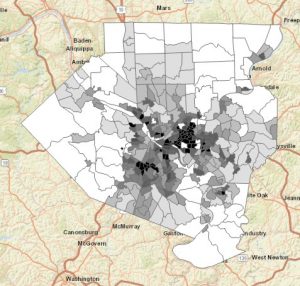
Mapping density is an invaluable technique for analyzing spatial patterns, allowing for a deeper understanding of how features are distributed across different areas. Depending on the type of data—whether lines, points, or defined areas—the approach to mapping density varies. If you have point data or lines, density can be mapped through graphical methods or density surfaces. For graphical methods, you might use dot density maps where each dot represents a certain number of features, visually demonstrating the distance between them. Density value maps, on the other hand, shade defined areas based on the number of features per unit area, offering a quick visual reference without pinpointing exact density centers. For more precise analysis, especially with point data or lines, density surfaces are useful. These surfaces assign density values to cells, and the patterns are displayed through shading or contours, which can highlight concentration areas more accurately but require more processing.
When mapping density for defined areas, consider factors such as cell size and search radius. Larger cells make for coarser maps with less detail, whereas smaller cells provide a smoother and more accurate map but require more intensive processing. The search radius affects pattern detail; smaller radii reveal more detailed patterns, while larger radii offer a more generalized view. Calculations can be simple, counting features within a cell radius, or weighted, giving more importance to features near the cell center. When transforming summarized data into a density surface, the center points of defined areas can be used to reflect the value assigned to each area, helping to highlight patterns with less emphasis on shapes.
Displaying a density surface involves choosing appropriate classification methods like natural breaks, quantiles, equal intervals, or standard deviations, which affect how patterns are visualized. Graduated colors or contours illustrate variations, with darker shades often representing higher values. It’s essential to find a balance in the number of classes to effectively show patterns without distorting the data. Interpreting these results requires understanding that the patterns observed may vary based on sample point distribution and the specific data layers used, as GIS calculations are tailored to each layer’s data.
Ch. 5
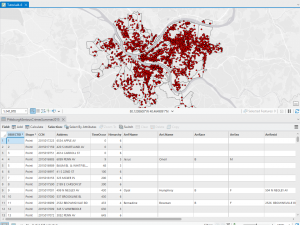
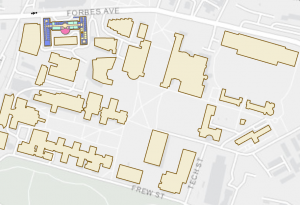
Mapping and analyzing what is inside a defined area involves several techniques to interpret spatial data effectively. The process starts with creating an area boundary, which allows you to identify and summarize the features within it. The method you choose depends on your data and the type of information you need, such as lists, counts, or summaries.
There are three primary approaches to finding what is inside an area:
- Drawing Areas and Features: This approach helps determine whether features are inside or outside a boundary.
- Selecting Features Inside the Area: Useful for obtaining a list or summary of features contained within the boundary.
- Overlaying Areas and Features: Effective for analyzing which features fall within which areas and summarizing data based on these areas.
When features partially intersect with the boundary, you need to decide whether to include the entire feature or just the portion inside the boundary. GIS can help by generating reports and statistical results based on your selected features. Overlaying multiple areas on a set of features allows for detailed summarization and comparison based on specific statistics.
The chapter highlights the importance of understanding what is inside a given boundary, which is crucial for applications like determining the impact of events within specific zones, such as assessing speeding violations in school zones. Choosing the right boundary—whether a service area, buffer, natural boundary, or manually drawn territory—affects how features are analyzed. Effective mapping involves creating a suitable boundary and using GIS tools to produce relevant reports and summaries based on the analysis of areas and features.
Ch. 6
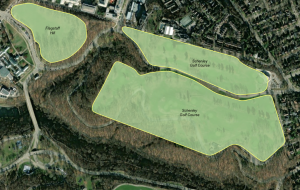
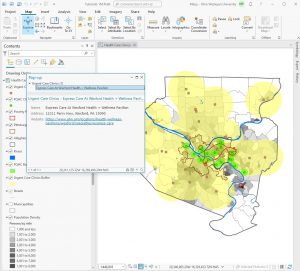
The chapter focuses on using GIS to map what is nearby a feature, measuring within a specified distance or travel range. This involves understanding how to define “nearness” based on the information needed from the analysis. Travel range can be measured by time, distance, or cost, and the choice of measure depends on the analysis requirements and how you define proximity.
For small distances, the planar method is appropriate as it assumes a flat surface, while the geodesic method is used for larger distances to account for the Earth’s curvature. Your choice of method should also consider the desired end result, whether a list, summary, or count, and the number of distance or cost ranges needed.
To find what’s nearby, there are three primary methods:
- Straight-Line Distance: Defines an area of influence around a feature using a fixed distance to create a boundary or select features within that distance.
- Distance or Cost Over a Network: Measures travel based on a fixed infrastructure like roads, capturing the cost or distance of travel between points.
- Cost Over a Surface: Measures overland travel to calculate the area within a travel range based on varying travel costs.
The chapter explains that mapping what is nearby involves creating buffers or rings around a feature to visualize the distance or travel range. It also discusses creating multiple buffers to assess how the total amount changes with distance or using distinct bands to compare distance to other characteristics. To create effective maps, you may use various visualization techniques such as point-to-point distance, color-coding, or spider diagrams. The process starts with data gathering and separation before mapping, emphasizing the need to choose appropriate methods and visualizations based on the analysis goals.