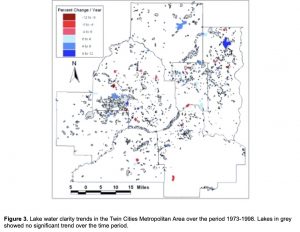
Chapter 1: Introducing GIS Analysis
GIS is a powerful tool for analyzing and visualizing data. It is used to map where things are, show concentrations (most/least), analyze density, finding what’s inside a specific area, and track changes over time. At the core of GIS analysis is the process of asking questions, selecting appropriate methods based on available and required data, processing that data, and interpreting the results in the form of maps, tables, or charts.
GIS data comes in several forms. Features can be discrete, meaning their locations can be pinpointed, or continuous, which can be measured anywhere. Features can also be summarized by area. These features are represented using either vector (coordinates) or raster (layers) data. The accuracy of representation depends on map projections (globally) and coordinate systems (specified area).
Each geographic feature in GIS has attribute values, which describe its characteristics. These values are classified into types such as categories, ranks, counts, amounts, and ratios (proportions and densities). This classification helps in selecting the appropriate analysis technique. Ultimately, GIS allows users to reveal spatial patterns and relationships that may not be obvious, making it an essential tool for decision-making in a wide range of fields.
Chapter 2: Mapping Where Things Are
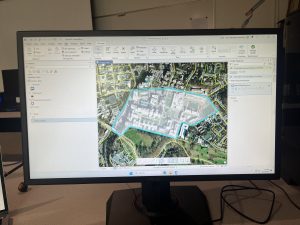
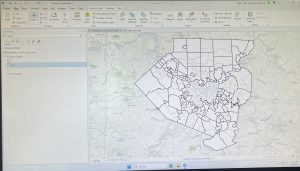
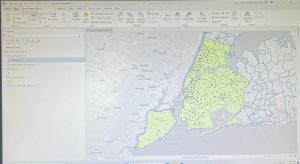
Mapping where things are is a foundational function of GIS that helps identify geographic patterns and relationships. Before creating a map, it is crucial to decide what information needs to be shown and why. GIS analysis allows users to pinpoint where features exist or where they don’t, identify their types, and determine their distribution. However, map design should balance detail and clarity, where too much detail can overwhelm viewers, while too little might leave out crucial data.
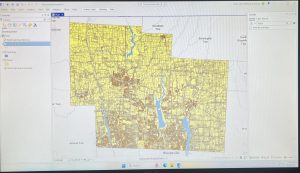
The first step in preparing data is assigning geographic coordinates or addresses to features. Each feature must also be assigned a category value that identifies its type. When making maps, there are many different approaches. You can map a single type using the same symbol, focus on a subset of features, or map by category, using distinct symbols for different types. If features belong to multiple categories, it’s important to visually distinguish each group, but it is suggested not to use more than 7 categories on one map. If more than 7 categories are needed, they should be grouped to avoid clutter.
Choosing symbols is essential for clear communication. Individual locations can be shown using color coded markers, linear features can vary in width or pattern, and areas may be differentiated using raster layers or shading. Text labels can also help in identifying areas. Including reference features like roads, rivers, or landmarks adds context, which can make a map more meaningful to the audience.
When analyzing geographic patterns, zooming out can help identify broader trends. Combining spatial patternswith background knowledge often reveals why features are arranged in a certain way. Well designed maps, supported by prepared and categorized data, allow GIS users to communicate spatial relationships effectively to an audience.
Chapter 3: Mapping the Most and Least
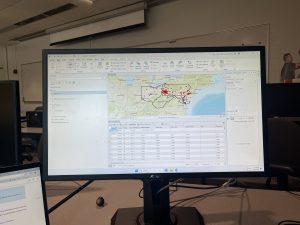
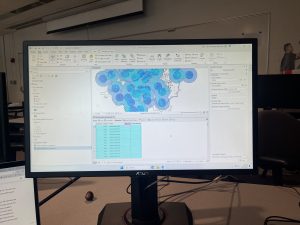
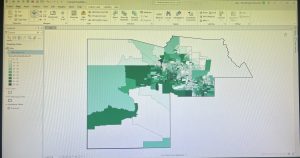
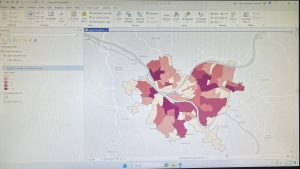
Mapping the most and least is a method in GIS used to explore how quantities vary across locations. This approach allows users to see relationships between places, revealing patterns not visible in raw data. This technique is especially useful for comparing counts, amounts, ratios, ranks, and densities across geographical areas. When mapping quantities, it is crucial to consider the audience, whether the map is exploratory or intended for presentation, influences the choice of using data or visual maps.
Understanding quantities is important. Counts represent the actual number of features, while amounts are total values associated with features. Ratios compare two values, while proportions and averages divide values to show relationships. Densities show distribution over space. Ranks order features from high to low, either through text (high, medium, low) or scales (1-10).
These quantities are often grouped into classes to make patterns easier to interpret. Creating classes of data helps readers compare areas more quickly, though this can reduce the precision of the data. There are several classification methods:
- Natural breaks (Jenks): classes are based on natural groupings of data values
- Quantile: Each class contains an equal number of features
- Equal interval: the difference between high and low values is the same
- Standard deviation: features are placed in classes based on how far away from the mean they are
When making a map, various visualization techniques can be used:
-
-
- Features: locations, lines, areas
- Values: counts/amounts, ratios, ranks
-
-
- Features: areas, continuous phenomena
- Values: ratios, ranks
-
-
- Features: locations, areas
- Values: counts/amounts, ratios
-
-
- Features: continuous phenomena
- Values: amounts, ratios
-
- Features: continuous phenomena, locations, areas
- Values: counts/amounts, ratios
Using these tools, GIS helps reveal spatial patterns in quantitative data.