Chapter 1:
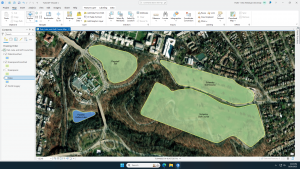
In a broad sense, GIS lets you see patterns and relationships in your geographic data. This chapter helps to teach about the process for Performing a GIS Analysis. The first step is to frame the question by figuring out what information you need, often presented as a question. Specificity is important in deciding which methods to use and how you are going to present the results. The next step is understanding your data. You have to be aware of what information you already have and what information you will need to obtain. Next, you have to choose a method by completing the necessary steps in a GIS. Lastly, you have to look at the results and make a decision on what information needs to be displayed/included to best understand your data.
Types of features:
- Discrete features → the actual location can be pinpointed. A feature with a clear and distinct location
- Continuous phenomena → phenomena that can be found/measured anywhere with no gaps. With continuous phenomena, a value can be determined at any given location. Ex) precipitation (cm)
- Summarize data → the counts or density of individual features found within area boundaries. Ex) number of houses in each county
There are two ways to represent geographic features in GIS: vector models and raster models. In a vector model, each feature is a row in a table and the shapes are defined by x and y locations in space. Features include discrete locations, events, lines, and areas. In a raster model, features are represented as a matrix of cells in a continuous space. Each layer of the model represents one attribute and analysis usually occurs by combining layers. Continuous numeric values are represented with the raster model. A map projection is used to translate locations on the globe onto a flat surface such as a map.
There are five attribute values including: categories, ranks, counts, amounts, and ratios. Categories are groups of similar things that help organize non continuous values. Ranks put features in order from high to low and are used when direct measures are difficult. Counts and amounts are used to show the total numbers, counts show the actual number of features on a map and amounts can be any measurable quantity that is associated with a feature. Ratios are used to show the relationships between two quantities. Categories and ranks use non continuous values while counts, amounts, and ratios all use continuous values.
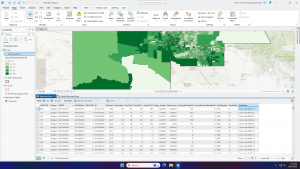
The last portion of this chapter talks about working with data tables. Selecting features to work with, calculating attributes and summarizing values to get statistics are all important for GIS analysis.
Chapter 2:
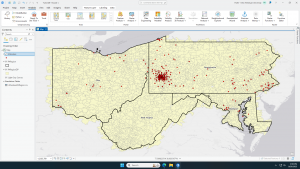
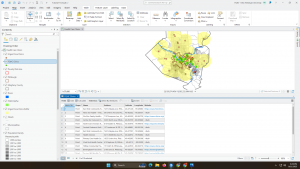
Chapter 2 focuses on mapping where things are everything that has to do with understanding where things are mapped and how to map them properly. When looking at the distribution of features rather than a singular feature, you can better understand patterns of a given area. To look for patterns, you have to map the chosen features in a layer by using different kinds of symbols. The map has to be understandable to your audience and the issue being addressed. The information will not effectively be shared if your target audience doesn’t understand what is being shown either with too much or too little information, confusing symbols, or overly complicated maps.
Preparing your data:
You have to first assign each feature a location using geographic coordinates. Then they must be assigned a code that identifies its type.
Making your map:
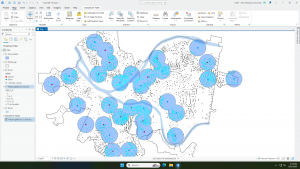
In order to create your map, you have to tell the GIS what you want to be mapped and which symbols to use to draw them. To map features as a singular type, use the same symbol. The GIS stores the data you input and uses the given coordinates to draw single or linear features. It can also represent areas by drawing outlines or filling areas with a specific color or pattern.Features can be mapped by category to provide an understanding of how a place functions such as the major road systems and traffic patterns. It is possible for features to be a part of multiple categories which can help reveal different unseen patterns. When showing multiple categories in a map, be sure to include no more than seven as any more can be difficult to interpret. Density of the features is also important to pay attention to as denser features should have fewer categories. If there are more than seven categories, you can group them which makes representing/understanding larger sets of features easier but may hide key information that could be helpful for interpretation. A good understanding of how you are grouping your data is crucial. Choosing the correct symbols can help to reveal patterns in the data. In order to make your map easier to understand, you can include recognizable features and features that reference your data/ help to interpret the message.
Analyzing Geographic Patterns
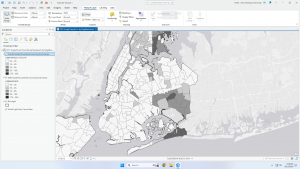
If mapped correctly, you may see some patterns emerge from your data such as clusters or random distributions. Patterns can be used to help explain why things are how they are. You can use statistics to find hidden patterns that cannot be easily seen or understood just by viewing the map.
Chapter 3:
Chapter three focuses on mapping the most and least so you can compare places to understand relationships. Mapping most and least map features rely on the quantity that is associated with each and leads to a deeper understanding. You’re able to map quantities that align with any of the three types of features that were discussed in chapter 1. This chapter highlights the importance of keeping a purpose for your map and ensuring you know your audience and their knowledge comprehension capabilities. With GIS you can explore data and how different patterns arise or you can present maps with patterns that tell a story or answer your question.
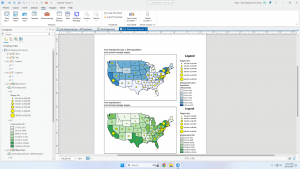
Quantities can be counts, amounts, ratios, or ranks. Knowing which type of quantities you have helps to determine the best type of map to present. The text talks about averages, proportions, and densities and how they relate to ratios. The next section discusses creating classes. Classes are grouped values that represent quantities on the map. Mapping individual values creates an accurate display of the data because no features are grouped together which ultimately allows you to search for patterns found in the raw data. Classes are used to group features with similar values together using the same symbol and these classes can be altered manually or by using a classification scheme. The text then goes over manual alteration and use of a classification scheme.
Comparing classification schemes:
- Natural breaks → finds groupings and patterns inherent in the data which means values in a class are most likely going to be similar. It’s good for mapping values that aren’t evenly distributed
- Quantile → each class has an equal number of features in it.
- Equal interval → Each class has an equal range of values. Best for presenting data to a beginner audience
- Standard deviation → each class is defined by its distance from the mean value of all the features.
As with any set of data, there is a chance for outliers. Using natural breaks can help isolate outliers. There are many different ways outliers can be caused so it is important to pay attention when they appear and double check your data.
Making a map:
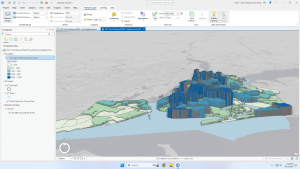
This section discusses creating the map after data value classification. When creating a map with quantities, you can use graduated symbols, graduated colors, charts, contours, or 3D perspective views.
- Graduated symbols → map discrete locations, lines, or areas
- Graduated colors → map discrete areas, data summarized by area, or continuous phenomena
- Charts→ map data summarized by area, or discrete locations or areas. Show patterns of quantities and categories at the same time
- Contour lines → show the rate of change in values across an area for spatially continuous phenomena
- 3D perspective views → used with continuous phenomena to help visualize the surface