Chapter 4:
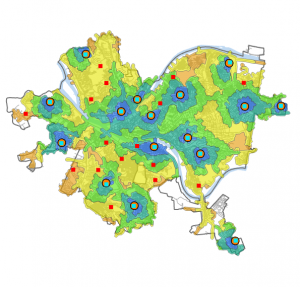
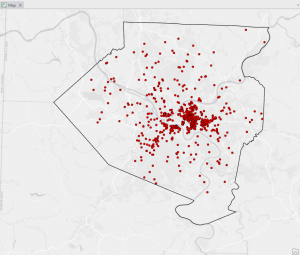
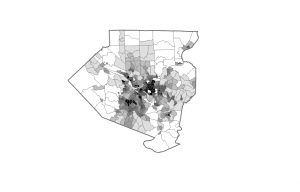
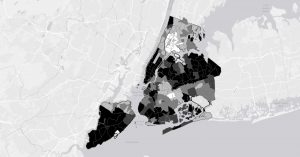
This chapter concentrated on mapping density, which illustrates varying concentrations of specific features and helps reveal patterns in the data. It can be applied in contexts like census maps and the frequency of robberies per square mile. GIS is a valuable tool for visualizing the density of certain points or lines, typically represented through a density surface. Density maps can be created based on the number of occurrences of a feature within a defined area or the values related to that feature. There are two main methods for generating density maps: using defined areas or creating a density surface. The first method, which focuses on defined areas, is more graphical and often employs dot maps. In a dot map, the proximity of the dots indicates the density of that feature in a specific location. To calculate the density value for each area, you divide the total number of features (or their overall value) by the area of the polygon. The second method involves creating a density surface, typically as a raster layer in GIS. Each area is assigned a density value based on the number of features within a certain radius. While this approach requires more effort, it offers greater detail than the first method, displaying the locations of features and continuous phenomena. Personally, I prefer the defined area method because it results in clearer and more understandable maps. The cell size in either mapping approach significantly influences the observed patterns; if the cell size is incorrect, the resulting patterns can vary, which can remind one of gerrymandering. To determine the cell size, you convert the density units to cell units, divide by the number of cells, and then take the square root to find the size of one side of the cell. Overall, I found this chapter fascinating. There’s much more complexity to density maps than I initially realized. I’ll likely need a textbook handy when I start working with the program this year, as there’s a lot to absorb.
Chapter 5:
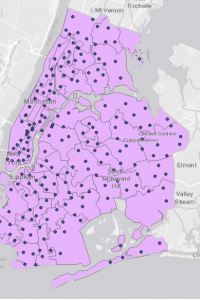
This chapter explores the “Finding What’s Inside” technique, a flexible tool for mapping areas to deepen understanding of their dynamics. It also facilitates comparisons between different regions, making it a valuable resource. The first method involves overlaying a boundary on the area’s features. The second method selects features located within this boundary, while the third combines these two approaches to produce summary data. This technique can uncover patterns within a specific area or across multiple regions. Categories can be either discrete or continuous, with continuous data potentially coming from earlier GIS maps. Area graphs can help determine whether a particular feature is present within an area, compile a comprehensive list of features in that area, or count the number of features in a specified region or set of regions. Since some linear or discrete data may extend both inside and outside an area, you can choose to include only data that is fully contained, completely outside, partially inside but extending beyond the area, or just the portions that are within the area. The first approach to “finding what’s inside” involves drawing boundaries over features. The next method selects features within a designated area, and another option overlays both areas and features. Different methods are more effective for different problem-solving contexts. When creating these maps, using bold lines or shading to define areas can enhance clarity. After developing these maps, statistical analysis can provide valuable insights into the data and highlight visual patterns. The chapter also outlines how to create various types of maps and the associated steps involved.
Chapter 6:
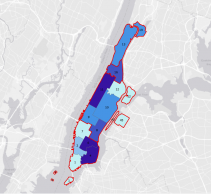
Mapping the area around a feature can be advantageous in numerous ways, such as estimating travel time from home to a store or tracking logging activities near a river or property line. The concept of “nearby” can be interpreted in different ways. For example, it could refer to a specific distance, like identifying all trees of a particular species within a mile of a river, or it might involve travel routes, such as how quickly a fire truck can reach a fire. When assessing proximity, measurement units can include more than just distance; considerations like time, cost, and effort are also significant. It’s also essential to decide whether to factor in the Earth’s curvature when calculating distances. There are three main methods for determining what’s nearby: straight-line distance, distance or cost over a network, and cost over a surface. While I’ve already discussed the first two, I’ll explain cost over a surface. This approach is especially useful for assessing travel costs over long distances, as it employs a raster surface to represent the costs associated with moving away from a feature across the map. Additionally, GIS allows you to select features within a given distance. By entering a distance from a source, it highlights all features within that range and provides a list, count, or summary of those features without the need for a defined boundary. However, when dealing with multiple sources, it’s crucial to label each feature to indicate which ones are near each source. Fortunately, GIS comes equipped with a built-in street network, so you don’t have to input any extra data when measuring distances or costs over a network.