Chapter 4
4-1 — This tutorial taught how to add new data to a project and make it readable by the program.
4-2 — I had an error with this tutorial. The book says to type “!GEOID10!” in the section where you calculate field for GEOIDNum, but in actually “!GEOID!” without the “10” worked perfectly fine, and gave me the ID without the leading zeros. Additionally, there was another error where they asked me to create 3 text fields through the attributes table which is not where you add fields.
4-3 — Much of this tutorial felt repetitive, as I believe we already learned (or at least it was very straightforward) how to select a range, and then only view selected items in the attribute table. Learning SQL was helpful, though.
4-4 — 4-4 Was about how to use Spatial Join to aggregate data.
4-5 — I simply could not get this one working, the tool would not run and I was unable to figure out why.
4-6 — I had accidentally broken the data value once when I wrote the inputs/outputs wrong, as the book did not disclose which was the proper logic. I managed to fix it later, though.
Chapter 5
5-1 — I’m a really big nerd for Map projections so this tutorial I found really interesting. It was fun to play with the different world maps.
5-2 — This chapter was the same as the previous, more or less, but for the U.S. instead of the world.
5-3 — I felt pretty confused over the purpose of this tutorial. I understand that it was to change the Coordinate systems the map used, but it had a bunch of extra information or things it wanted me to do that felt completely arbitrary or irrelevant.
5-4 — This was a confusing and conflicting Chapter. I couldn’t find the “Display XY Data” option they were talking about. Then, they said to delete the Libraries Table, but there were later steps that required the Libraries Table.
5-5 — Completing this section requires waiting 40 minutes for a 1.4 Gigabyte download.
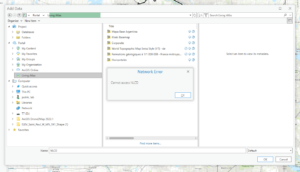
5-6 — I received an error message when trying to access NLCD that said “Network Error: Cannot Access NLCD”
Chapter 6
6-1 — This tutorial was incredibly confusing, and I was barely able to figure out what it wanted for the final part of it. My only question is what does normalization do? The final “Your Turn” asked for symbolizing with graduated colors using the field Sum_TOT_POP and normalizing it with Sum_SQ_MI.
6-2 — This taught how to select certain features within an area, then how to clip them to fit entirely within it.
6-3 — I encountered an error at the end in which I was unable to merge the NYC Waterfront Parks into one layer. There was not much information on the error message so I was unsure how to fix it.
6-4 — This showed how to use the append tool to merge data.
6-5 — This section showed how to merge data from an area feature to streets. It seems useful to be able to know what streets are in what division.
6-6 — This was more about merging and summarizing data from tables.
6-7 — When told to do the summary statistics for the total number of disabled people per Fire zone, I was able to figure out which was the correct Input, case field, and statistic field to input to get the proper summary statistics without looking back at the book.
Chapter 7
7-1 — This quick section covered how to edit polygons on maps. It’s nice to finally learn how to edit features after 7 chapters of tables and computing
7-2 — Learning to create the features for the feature class finally was also nice.
7-3 — Having smoothing done by an algorithm seems to be helpful so I wouldn’t have to worry myself about making it perfectly smooth.
7-4 — The transform tool was slightly hard as I could not find the exact vertex of the layer I was transforming.
Chapter 8
8-1 — I wish that more often the book would tell us exactly what each part of each tool does and why it’s needed. It can be confusing just filling out these tools without it. This chapter’s introduction was very helpful in understanding the tools, though. I feel like I was really understanding what the tools did and how they worked rather than just confused clicking.
8-2 — This section I feel the same way, although this was slightly more confusing, as none of the fields were explained fully for the create locator tool. I think that maybe a table or chart that fully explains each tool we use would be helpful.