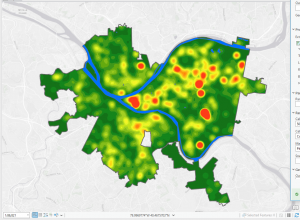
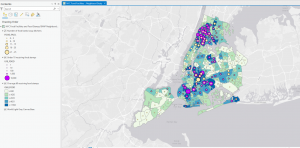
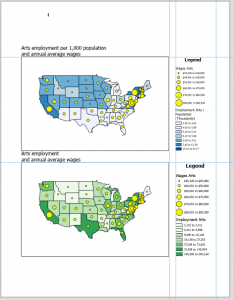
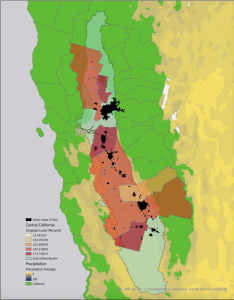
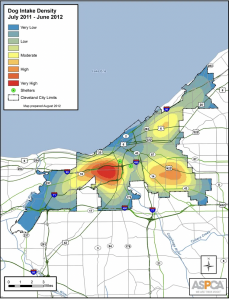
Chapter 4: Mapping density explores techniques used in GIS to visualize data concentration and distribution. Mapping density shows where the highest concentration of features are, making it useful for identifying patterns. Areas with many features may be difficult to analyze visually, so density maps allow measurement using units like hectares or square miles to better understand distribution. This is useful in mapping things like census tracts or counties. The chapter highlights two main ways for density mapping, by defined area and by density surface. Defined area mapping uses dot density maps, where each dot represents a specified quantity of a feature. A shaded density map can also be used, where polygons are colored based on density values. Density surface mapping is created in the GIS as a raster layer. Each cell in the raster layer receives a density value based on the number of features within the radius. When deciding how to map density, it is important to consider the features being mapped and the information needed. Density mapping can focus on features or feature values, which can lead to different interpretations. Displaying density surfaces effectively requires careful classification of data values. Common classification methods include: Natural breaks, quantile, equal interval, and standard deviation. Choosing the right number of classes is important- too many can make patterns hard to distinguish, and too little may oversimplify. Density surfaces are typically displayed using a single color gradient, with darker shades representing higher density. Contours can also be combined with shaded density surfaces. Overall, chapter 4 provided a good understanding of density mapping and its significance in GIS analysis.
Chapter 5: Finding what’s inside discusses how GIS allows users to analyze what is inside a specific area, which is important for monitoring and comparing multiple regions. Mapping what is inside an area helps identify patterns, summarize key features, and support decision-making processes. The chapter introduces three primary methods for determining what is inside a given area: drawing areas and features, selecting features inside an area, and overlaying the areas and features. Drawing areas and features is the simplest method, allowing you to create a visual boundary around an area and examine what features are inside or outside. However, this method is purely observational and lacks quantitative data. Selecting features inside an area is a more detailed approach, because GIS can generate lists, counts, or summaries of the features within a defined boundary. The most comprehensive method is overlaying areas and features, where GIS combines the area and its features into a new layer with attributes from both. The chapter also talks about discrete and continuous features. Discrete features are individually countable items, such as businesses or crimes, while continuous features represent measurements that vary over space, such as elevation or weather. The choice between vector and raster overlay also impacts the accuracy of the analysis. Vector overlay provides precise areal measurements but requires more processing, while raster overlay automatically calculates areal extents but may be less accurate.
Chapter 6: finding what’s nearby focuses on what is near a specific feature. This type of analysis is essential for monitoring surrounding areas, measuring distances between features, and understanding spatial relationships. GIS allows for finding what is nearby by using three main methods: straight-line distance, distance or cost over a network, and cost over a surface. Each of these methods has its own practical applications and limitations, making it important to choose the right approach based on the type of data and analysis being conducted.
Straight-line distance is the simplest method and is commonly used to create a boundary around a feature. This technique is useful when a fixed range is required, such as identifying all homes within a 500-foot radius of a proposed construction site. However, it does not account for real-world barriers like roads, rivers, or elevation changes, which can affect actual accessibility. Distance or cost over a network is a more advanced method that considers travel constraints such as road networks or transit systems. This is particularly useful for measuring travel time to a location, such as determining emergency response times for a fire station. Unlike straight-line distance, this approach provides a more accurate representation of accessibility since it factors in infrastructure. Cost over a surface takes analysis a step further by incorporating the effects of terrain and environmental conditions. Instead of following fixed pathways like roads, it measures travel costs based on real-world conditions, such as steep slopes, water bodies, or different land covers. This method is commonly used for overland travel analysis, such as identifying suitable areas for hiking trails or wildlife movement. Overall, Chapter 6 builds on previous GIS concepts by shifting the focus from what is inside an area to what is nearby. By using different proximity analysis methods, GIS provides valuable insights for decision-making in urban planning, emergency response, environmental monitoring, and transportation analysis. Understanding how to find what is nearby is important for making informed spatial decisions.