Chapter 4:
This chapter shows us how to map densities using the GIS, and why this can be useful to many people, from business owners to the average person looking to find out what’s within 1,000 feet of them. To put it simply, mapping densities shows you exactly how values vary across a region as well as where the highest/lowest concentration of a feature is. It is very useful in analyzing patterns and measuring the number of features using a uniform area unit such as square miles or hectares. A common use for density mapping is census tracking of population densities. Other common uses include locations of different businesses, and the number of employees in each business.
There are 2 common ways of mapping densities;
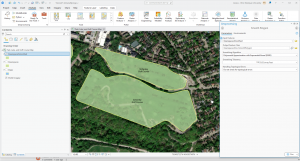
By defined area: This method is typically used if you want to compare areas with defined borders. It can be done with geographic mapping, dot mapping or by calculating a density value for each location. Dot maps are usually used to represent individual locations (eg. trees) and density values can be calculated by dividing the total number of features by the area of the polygon.
By density surface: A density surface is typically created by the GIS as a raster layer. Each cell in the layer is a density value (eg. no. of businesses within a square mile) based on the number of features within the radius of the cell. This provides very detailed information, but requires a lot of time, effort and storage. This method can be useful if you have individual locations, sample points or lines. One practical bit of advice in regards to this method was that you can use the GIS to change the sizes of the dots based on their densities in a map.
The chapter also goes over how you can use the GIS to create a density surface; convert density units into cell units, divide this value by the number of cells and take the square root of this value to get the cell size. It also gives more information about different data categories (eg. natural breaks, standard deviation) and gives advice on how best to use colors and contours to display your data. Overall, I think the chapter explained the process and intricacies of mapping densities in GIS very well. It did make me wonder if the mapping process changes when you are mapping over different surfaces, eg. land and water.
Chapter 5:
This chapter focuses on mapping what is within a certain region or border. People can want to do this for many reasons, but one of the more common ones is to compare different areas based on what is within them, eg. monitoring drug arrests within 1,000 feet from a school.
One of the key steps in this process is defining your analysis. To do this with the GIS, you must draw an area boundary on top of the features and use the boundary to select the features within it and list/summarize them. The area boundary and feature data can also be combined to create summarized data. In order to effectively carry this out in GIS, you need to consider 1) how many areas you have at your disposal and 2) what types of features are inside the area. One type of area boundary is a single area. Types of service areas include;
- A service area around a central facility (eg. a library district)
- A buffer that defines a distance around some features (eg. a stream off limits to logging)
- An administrative/natural boundary
You could also choose to work with multiple areas. Types of these include;
- Contiguous (eg. zip codes, watersheds)
- Disjuncts (eg. state parks)
- Nested (eg. 50- and 100- year floodplains)
Similarly to previous chapters, chapter 5 also briefly touches on the different kinds of features; discrete features (unique, identifiable features such as student addresses or locations of eagle nests) and continuous features (features that represent seamless geographic phenomena). I found this section to be very useful because it reminded me of the different feature types you can deal with in GIS, and encouraged me to do my own research into how they can appear and be displayed in GIS.
Finally, the chapter covers the three ways of finding what is inside:
- Drawing areas and features: You can use the GIS to create maps to see whether one or a few features are inside or outside a boundary
- Selecting the features within the area: Specifying the area and layer containing the features you want can help you get a list of features within one or multiple groups.
- Overlaying the areas and features: Combining the area and features to create a new layer with attributes of both can help you find out how much of a specific feature is in one or more area
Chapter 6:
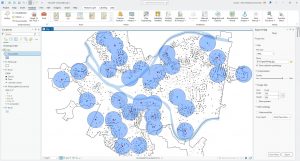
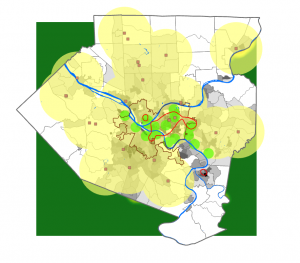
This chapter went over how you can utilize GIS to find out what is nearby you or another location altogether. Finding what is within a set distance can help identify an area, as well as the features inside the area that have been affected by an event or activity. One example of the GIS being used in this way is notifying residents within 1,000 feet of an accident. It can also be used to define the area served by a facility (eg. a library) and delineate areas suitable for a specific purpose. One example of this would be a wildlife biologist mapping an area within a half mile of a stream.
The textbook states that in order to find what is inside a set distance, we need to define and measure the concept of “near”. It can be defined by a set distance or the travel to/from a feature. And it can be measured by distance and cost. When analyzing the surface of the earth, we can either look at it with the flat plane method (typically used with small areas of interest) or the geodesic method (normally used with larger areas of interest such as continents). We also got an explanation of the 2 ways we can specify a range; inclusive rings (useful in finding out how total amounts increase as distances increase) and distinct bands (useful in comparing distances to other characteristics, such as the number of customers within a 1000 vs 2000 year range).
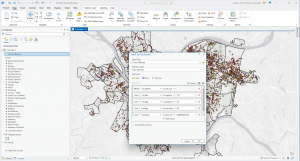
And finally, in the section I thought was the most interesting, the textbook covers the 3 ways of finding out what is nearby;
- Straight-line distance: By specifying the source feature and the distance, the GIS can find the area or the surrounding features within the distance. This method can be good for creating a boundary.
- Distance/cost over a network: Specifying the source locations and a distance/travel cost along a linear feature can help you find what is within a travel distance/cost of a certain location.
- Cost over a surface: Specifies locations of source features and a travel cost.
Overall I thought this chapter was intriguing because of how relatable it is to the lives of many people. The average person on most days most likely uses GPS technology everyday to find locations nearby them (eg. supermarkets, restaurants) to learn more about what is in their area. The information in this chapter can also be useful to those who wish to conduct scientific research and analyze data (eg. a wildlife conservationists who want to look at residential areas near a riverbank). This chapter also made me anticipate working with the GIS software later in the semester and doing my own investigations with the data provided.
 Introduction:
Introduction: 