Data 1: PLSS – This is a feature layer, PLSS meaning Public Land Survey System. It was created to facilitate the PLSS and boundaries for the US and Virginia Military Survey Districts of Delaware County It is updated on an as-needed basis
Data 2: Township – Feature Layer: This shows all the townships that are in Delaware County.
Data 3: 2024 Aerial Imagery: Spring 2024, planes flying over Delaware county in spring
Data 4: Delaware County E991 Data – Feature Service: This map shows the 991 emergency response, accident reporting, geocoding, and disaster management in Delaware County. It helps 911 agencies comply with phase II 911 requirements
Data 5: Building outline 2021 – Feature Layer: This shows the outlines for all the structures in Delaware County in 2021, when it was last updated.
Data 6: Original Township – Feature Layer: This is a map of what the original township boundaries were. This was before tax district changes affected township shapes.
Data 7: Zip Code – Feature Layer: All the zip codes in Delaware County are in here. Tax-exempt parcels were added by whichever zip codes they were most related to.
Data 8: School District – Feature Layer: This contains all the school districts in Delaware County. It was created by the Delaware County Auditor’s parcel records of the school districts.
Data 9: Building Outline 2023: Same as Data 5 but for year 2023.
Data 10: Recorded Document: A map that shows all the recorded documents in the Delaware County Recorder’s Plat Books, Cabinet/Slides, and Instruments Records. Some of these documents include ones containing vacations, subdivisions, centerline surveys, surveys, annexations, and miscellaneous. It is updated weekly and posted monthly.
Data 11: Dedicated ROW: Contains all the lines that are designated as right-of-way in Delaware County. They are stores within Delaware County Recorder’s office. There are currently 1256 records.
Data 12: Subdivision: This contains all subdivisions and condos in Delaware County. Currently 5917 records.
Data 13: Address Point: Represents all the certified addresses in Delaware County. There are currently 113797 records.
Data 14: Map Sheet: Shows all the map sheets in the county.
Data 15: Farm Lot: This shows all the farmlots that are in both the US and Virginia Military Survey Districts of Delaware County. 2077 records
Data 16: Annexation: This shows all the annexations and conforming boundaries since 1853. 421 records
Data 17: Survey: This represents the surveys of land in Delaware County. Old survey volumes 1-11 are not included. 17848 records
Data 18: Tax District: This shows all of the tax districts in Delaware County. 61 records
Data 19: Hydrology: This shows all the major waterways in Delaware County. It was enhanced in 2018 with LIDAR-based Data. 24 records
Data 20: GPS: This shows all the GPS monuments in Delaware County. 351 records
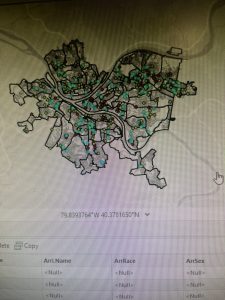
Here is a screenshot of center streetline, hydrology, and parcel: