Chapter 1:
Chapter 1 begins with a brief introduction which describes how the GIS industry has grown and evolved since the original edition of the book was published in 1999. Additionally, there is a short section on the structure of the book and what one can hope to learn by reading it. The author then describes what GIS analysis is and how each analysis begins with a question that you are hoping to answer, and is influenced by factors like how your research will be used and who will use it. These questions, along with the format and form of your data, the methods by which you process it, and how precisely you are attempting to answer your questions all have additional effects on your analysis methods, and ultimately how your results are created. After this, the next section deals with the various geographical features and how they can be displayed. There is then a comparison of discrete vs continuous features and a description of what data summarization is, with examples on where it can be applied, such as number of features or average altitude for some region. Following this, the author compares 2 ways of representing features on the map, that being raster graphics, which displays features as sets of cells in a grid, and vector graphics that defines objects by sets of points making up its border. Finally, the chapter concludes with a description of various attributes that features can have, including rank, which can be used to categorize objects from highest to lowest value, and ratios between attributes, like population and land area that objects also have, followed by a brief section about summarizing and working with data tables.
Key Concepts:
Discrete Features: Features that either are or are not present at any given location, such as property lines, roads or county lines.
Continuous Phenomena: Factors that are found across an entire region and can exist at any value in some range, such as amount of rain, altitude, or soil type.
Raster Graphics: Displays objects as cells in a grid which displays features as sets of cells in a grid
Vector Graphics: Features are formed by sets of points in specific points on the map.
Chapter 2:
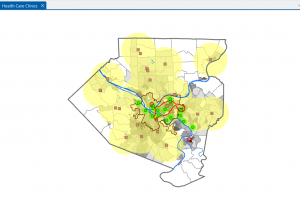
Chapter 2 begins with a section outlining the purposes of mapping, and how to choose what features you would like to map. By mapping the locations of events or features, the text explains, you can find trends in where they occur. For each feature on the map, it must have a location and any additional information associated with it, such as speed limit if the feature was a road, or median housing price if the feature was a certain region of zip codes. Within each category a feature may fit in, like houses in a city, additional subcategories can be added, such as single vs multiresidence housing. Categories can also be grouped to simplify the map and make overarching patterns easier to understand. However, grouping categories must be done with care, as depending on the groupings chosen, trends may vary greatly. Symbols also play an important role in the representation of objects with a specific location, like the locations of houses, or traffic lights. Shading can be used to represent features like zoning districts, while lines can represent features such as rivers or roads, with attributes such as color and width being used to further show differences between features. By analyzing the patterns formed by the features we map, we can find patterns that ultimately allow us to draw conclusions about the data we represent. For example, by mapping soil types and rainfall patterns, we could make determinations about which land in an area would be most suitable for farming, or by mapping house fires in a town, we could determine which areas would most benefit from the construction of a new fire station.
Key Concepts:
Category: A specific value representing a characteristic that some data object has, usually out of a set of possible values.
Grouping categories: The practice of grouping a set of objects with similar characteristics to make visualization easier
Symbol: A marker used to denote the location of individual objects of some specific feature, often with different symbols used to represent different feature types
Chapter 3:
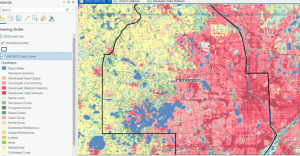
Mapping the most and least gives us information about where features are and are not found, allowing us to understand the relationships between location and feature distribution. Shading, varying feature size and color can all be used to show how quantities of features vary across maps, with some methods, like shading being more applicable to areas, while others like size are better applied to individual objects like markers. While it is important to keep in mind the distinction between exploring the data and presenting a map to display a specific pattern, you often begin with exploring the data, followed by mapping to show the patterns you find. Ratios can also be a useful feature for summarizing data, since they can often display patterns better than raw numbers allow for. For example, the ratio between housing and businesses for a city can give a more accurate representation of land use than simple counts would. Ranking is also a process used for displaying relationships between features, in which a set of objects is listed from highest to lowest, such as ranking regions from greatest to least rainfall, or ranking streets from highest to lowest traffic flows. Classes can also be used to generalize data, and are usually formed by grouping features by the value of some attribute, like household income or soil type. Classes can be manually determined to best fit the data, or in some cases by using standard classification schemes, the 3 most common being standard deviation, equal intervals, quantile, and natural breaks, each of which has its specific advantages and disadvantages. In the process of making a map, the goal is to display the patterns as accurately and clearly as is possible, which can be done by focusing on the patterns you are trying to convey information about and by choosing a map styling that fits the data you are displaying. There exists a variety of map stylings, each applicable to a different scenario. Graduated symbols easily show the rank or relative size of features, while graduated colors can be applied to maps showing data by area, like population by township, or forested land in each census tract. Charts can be used to show ratios between a set of features in each area on the map, but can become cluttered if too many are used too close together, or if too many categories are used. Contour lines show the rate of change for continuous features, like showing changes in elevation for a mountain range, or clay content in soil for a county. A 3D view can be used to show continuous phenomena, with height usually representing the magnitude of the value at that point. Ultimately, if the map is made correctly, it should be able to convey the data it is trying to display in a clear and understandable way, allowing its audience to understand and gain insight into the trends that are present.
Key Concepts:
Ratios: Using averages, proportions and densities to better understand and display patterns, showing the relationship between two different quantities
Ranks: Putting features in order from greatest to least, showing quality relationships rather than quantitative values.
Classes: Groupings of features based on values in order to make generalizations to data.