Chapter 4
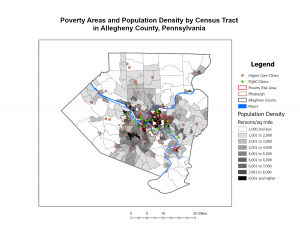
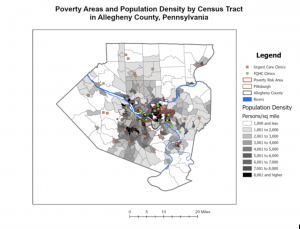
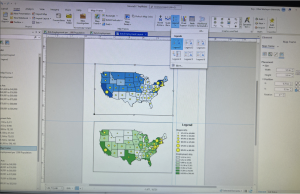
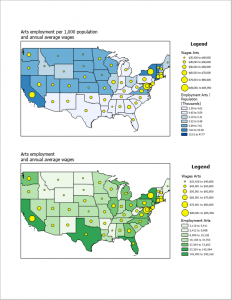
Often, GIS can be used to map density as a manner in which to clearly represent areas of highest concentration- such as with feral cats or oversized rats- for the purpose of seeking out various patterns. For example, oversized rat phenomena could be located in large urban centers due to the access of food, adaptations, etc, but maybe their oversized rats can be found in a rural area that is coincidentally near a nuclear waste site. Things such as the United States Census records data that can be used for density mapping for population, income, family size, etc. There are also two different options of representing density as density of features or feature values. As an example, density of features would show the areas with oversized rats while feature values would show the number of oversized rates in the areas. In addition, there are two manners of mapping density either by area or by surface, each with their own uses and drawbacks depending on the type of data you have and what you want to do with it. Some data can be best represented using individual points while other data is best represented using shades of color. For example, for relatively isolated incidents of the oversized rat phenomena, a dotted map could be used to examine relationships between rat outbreaks. However, if incidents of oversized rats become a prevalently explored and recorded phenomena, then a shaded map would become better suited to facilitate pattern recognition. GIS has the computing power to be able to make calculations with density data to generalize and present density data in a manner conducive for seeking out patterns within the data.
Chapter 5
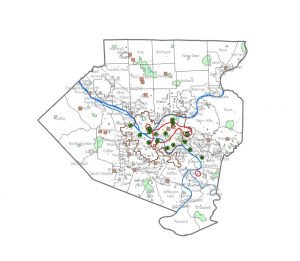
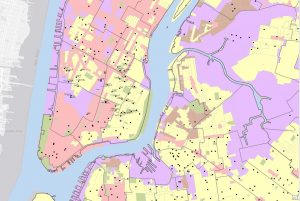
When mapping a subject within the boundaries of an area, patterns within the area may be assessed or internal patterns can be compared to the patterns within other areas. Using feral cats as an example, feral cat information could be tracked with Delaware City’s Township and compared with other townships- within or outside of the county- to track patterns in where feral cats are the most prevalent. With that information, trap, neuter, vaccinate, and release programs can be sent out to places with the most need in order to manage cat populations. This information could also be used to find cats or kittens that could possibly be integrated into human households. The power of GIS allows users to use pre-established boundaries- i.e. counties, townships, zip codes, etc., or created boundaries to assess data depending on the intended span and use for the data. Determining whether the features are continuous or discrete is important when mapping data within. Discrete data would be the number of feral cat colonies whereas continuous data encompasses things such as elevation, vegetation types, temperatures, precipitation, etc. that are continuously present. GIS can be used for lists of features, the numbers of features, and for summaries, and GIS can be used to cut off certain data that is outside of a drawn boundary. From that point, there are three methods of finding what’s inside: drawing boundaries to show features outside and within, specifying an area, or to create a new layer that overlays the original. Each method, like the others, has its own uses depending on your goals for your data and analysis. Summaries for numerical data can also be implemented such as sum, mean, median, and standard deviation depending on the relevance of each for the best representation of data. To best express the need for managing feral cat populations within the city of Delaware, I may want to use the sum of cats or average number of feral cats per square mile to stress the gravity of the problem.
Chapter 6
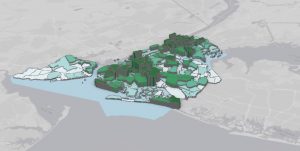
As a counterpart to Chapter 5’s finding what’s inside is Chapter 6’s finding what’s nearby within a certain distance or range. An example of using range would be notifying people within a ten-mile radius of a colony of rabid bats. This can be used for distance but also cost through time, money, or effort. Maybe I wanted to let everyone know about the rabid bats that are a breezy five-minute walk away from their community park. With this knowledge of the proximity of rabid bats, I could better raise community awareness and issue warnings for pets, children, and nighttime park-dwellers to be wary of the rabid bats and remind them of the mortality rate of rabies. An alternative would be to determine the travelling pattern of my rabid bats to best alarm those in the path of rabidity. GIS has the power to draw my ten-mile bat radius and measure my five-minute walking time. Depending on my goals for rabid bat analysis, I could calculate distance if the Earth was flat, using the planar method, or incorporate the Earth’s curvature, using the geodesic method. The planar method would be ideal for a smaller area of interest- a city, county, or state, but the geodesic method would be necessary for any larger analyses- such as if my rabid bats spread from my little town to all contiguous US states. Just as with mapping what’s inside, data can be represented using lists, counts, or summaries depending on need. I would like a list of the addresses within a ten-mile radius of my rabid bat colony to ensure their awareness of the bats and to ensure that they have not yet gone rabid. In the aftermath, I would perhaps seek a count of the rabies cases in a post-rabid bat town, and perhaps I would seek statistics or graphs to easily review the impact of my rabid bats on pets, children, and those nighttime park-dwellers. The three manners of finding what’s nearby include straight-line distance- such as a ten-mile radius, distance or cost over a network- such as sidewalks, and cost over a surface- such as for the travel cost to reach my rabid bats.