Chapter four discusses mapping density and how to show the highest concentration of features. This is useful for interpreting, identifying, and analyzing patterns. There are different ways to map density. These include shading defined areas based on density or creating a density surface. This method can be decided based on analyzing the data you have. The density of points or lines is usually done using a density surface method while you can also map data that has already been defined by defined areas. You also need to look at whether you are mapping features or feature values. This is an important distinction for analyzing. As far as the two methods go, you should map density by area if you have data that is already summarized by area or you have lines/points that can be summarized by area. This will produced a shaded fill map or a dot density map. A good thing about this method is that it is fairly easy to do, but it does not pinpoint the actual centers of density so it is not terribly precise in some situations. You should use the second method, creating a density surface, if you have individual locations, points or lines. This will produce a shaded density surface or contour map. This gives a more precise view, but is also more complicated involving more data processing. The chapter also describes in detail how to achieve both of these methods. Another concept it covers is the search radius. The size of the search radius matters because if it is larger the patterns are more generalized while if it is smaller it shows local variation.
Chapter five covers mapping “what’s inside”. This is important because it allows you to monitor what’s occurring inside an area or to compare with other areas. There are different forms of data for this type of mapping. One is a single area. This can include things such as an administrative or natural boundaries, an area you draw manually, and the result of a model, etc. Another form of data is multiple areas. This can include contiguous such as zip codes, disjunct such as state parks, and nested such as floodplains. An important thing to look at is if the features are discrete or contiguous. Discrete features are unique and identifiable. They can be counted and quantified. Contiguous features are seamless geographic values. From the analysis, you need to discover if you need a list, count, or summary and if you need to see features that are inside or partially inside the area. The book lists three ways to find what’s inside. These include drawing areas and features, selecting the features inside the area, and overlaying the areas and features. Drawing areas is a good method to discover if features are inside or outside and its a fairly simple method, but is only visual. Selecting the features will give you a list or summary, so it is good to get information about a specific area, but does not tell you about things on the edge of a specific area. The overlaying method is good for both finding and displaying what is in different areas, but requires more data processing and is more complex.
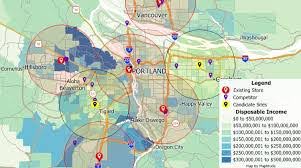
Chapter six talks about finding what is nearby. This is important because it allows you to look not only at features inside an area, but also what is outside and nearby an area. This can help provide context to an analysis which can help identify patterns. The first step is to define what constitutes both near and far. You can do this in many ways such as distance and cost. The information you need from the analysis is if you need a count, list, or summary and how many distance or cost ranges are necessary. There are three ways that you can find what is nearby. The first way is straight line distance. This is useful for creating boundaries and selecting features at a set distance away. The second way is distance or cost over a network. This is useful for finding what is within a set distance or cost. The third way is cost over a surface. This is useful for calculating overland travel costs. Which one to choose depends on what you are trying to accomplish and what data you have.